迈进新时代
80386使用了升级版的段式存储管理, 听上去很不错, 但实际上并不是这样.
回忆课堂内容, 段式存储管理有什么缺点? (说不定考试会出这道题喔 ^_^)
尽管这个升级版的段式存储管理是80386提出的, 但在手册上也提到可以想办法"绕过"它来提高性能: 将段的基地址设成0, 长度设成4GB, 这就是i386手册中提到的"扁平模式", 这样虚拟地址就和分段之后得到的线性地址一样了. 当然, 这里的"绕过"并不是简单地将分段机制关掉(事实上也不可能关掉), 毕竟段级保护机制的特性是计算机法制社会最重要的特征, 抛弃它是十分不明智的.
超越容量的界限
为了克服分段机制的缺点, 80386作出了计算机发展史上又一个具有里程碑意义的贡献: 提供了分页机制. 当然, 80386刚建立的时候, 它不能强迫大家使用分页机制, 因此80386也提供了一个神奇的开关, 只有打开了开关才能启用分页机制. 这个神奇的开关在CR0寄存器中的PG位, 分页机制只能在保护模式下启用, 这也算是给8086时代的程序一个过渡的选择.
回忆课堂内容, 页式存储管理有什么优点? (说不定考试也会出这道题喔 ^_^)
正是因为这些优点, 在现代的通用操作系统中, 分页机制基本上"取代"了分段机制, 成为计算机存储管理的主要方式.
gcc编译程序时也默认假设程序将来运行在扁平模式下. 你可以在 kernel/src/start.S 中进行以下尝试:
- 在kernel中为GDT增加一个新的段描述符, 它的基地址改为
0x4000000, 其它属性和数据段一样 - 把这个新的段描述符装载到SS寄存器, 作为新的堆栈段
- 把
%esp的初值改成0x4000000
修改后, 运行任意用户程序, 你会发现NEMU输出 HIT BAD TRAP 的信息. 分析相应的汇编代码, 你能厘清运行出错的根本原因吗?
我们也是先上一张图给大家一个感观上的认识:
PAGE FRAME
+-----------+-----------+----------+ +---------------+
| DIR | PAGE | OFFSET | | |
+-----+-----+-----+-----+-----+----+ | |
| | | | |
+-------------+ | +------------->| PHYSICAL |
| | | ADDRESS |
| PAGE DIRECTORY | PAGE TABLE | |
| +---------------+ | +---------------+ | |
| | | | | | +---------------+
| | | | |---------------| ^
| | | +-->| PG TBL ENTRY |--------------+
| |---------------| |---------------|
+->| DIR ENTRY |--+ | |
|---------------| | | |
| | | | |
+---------------+ | +---------------+
^ | ^
+-------+ | +---------------+
| CR3 |--------+
+-------+
80386采用了二级页表的结构, 为了方便叙述, 80386给第一级页表取了个新名字叫"页目录". 虽然听上去很厉害, 但其实原理都是一样的. 每一张页目录和页表都有1024个表项, 每个表项的大小都是4字节, 除了包含页表(或者物理页)的基地址, 还包含一些标志位信息. 因此, 一张页目录或页表的大小是4KB, 要放在寄存器中是不可能的, 因此它们也是放在内存中. 为了找到页目录, 80386提供了一个CR3(control register 3)寄存器, 专门用于存放页目录的基地址. 这样, 页级地址转换就从CR3开始, 一步一步地进行, 最终将线性地址转换成真正的物理地址, 这个过程称为一次page walk. 同样地, CPU也不知道什么叫"页表", 它不能识别一段数据是不是一个页表, 因此页表的结构也需要操作系统事先准备好.
我们不打算给出分页过程的详细解释, 请你结合i386手册的内容和课堂上的知识, 尝试理解IA-32分页机制, 这也是作为分页机制的一个练习. i386手册中包含你想知道的所有信息, 包括这里没有提到的表项结构, 地址如何划分等.
- 80386不是一个32位的世界吗, 为什么表项中的基地址信息只有20位, 而不是32位?
- 手册上提到表项(包括CR3)中的基地址都是物理地址, 物理地址是必须的吗? 能否使用虚拟地址或线性地址?
- 为什么不采用一级页表? 或者说采用一级页表会有什么缺点?
页级转换的过程并不总是成功的, 因为80386也提供了页级保护机制, 实现保护功能就要靠表项中的标志位了. 我们对一些标志位作简单的解释:
- present位表示物理页是否可用, 不可用的时候又分两种情况:
- 物理页面由于交换技术被交换到磁盘中了, 这就是你在课堂上最熟悉的Page fault的情况之一了, 这时候可以通知操作系统内核将目标页面换回来, 这样就能继续执行了
- 进程试图访问一个未映射的线性地址, 并没有实际的物理页与之相对应, 因此这就是一个非法操作咯
- R/W位表示物理页是否可写, 如果对一个只读页面进行写操作, 就会被判定为非法操作(还记得我们在PA2的最后在GNU/Linux下实施代码劫持攻击的时候引入的
mprotect()系统调用吗?) - U/S位表示访问物理页所需要的权限, 如果一个ring 3的进程尝试访问一个ring 0的页面, 当然也会被判定为非法操作
程序设计课上老师告诉你, 当一个指针变量的值等于NULL时, 代表空, 不指向任何东西. 仔细想想, 真的是这样吗? 当程序对空指针解引用的时候, 计算机内部具体都做了些什么? 你对空指针的本质有什么新的认识?
和分段机制相比, 分页机制更灵活, 甚至可以使用超越物理地址上限的虚拟地址. 现在我们从数学的角度来理解这两点. 我们知道段级地址转换是把虚拟地址转换成线性地址的过程, 页级地址转换是把线性地址转换成物理地址的过程, 撇去存储保护机制不谈, 我们可以把这两个过程分别抽象成两个数学函数:
y = seg(x) = seg.base + x
y = page(x)
可以看到, seg() 函数只不过是做加法. 如果仅仅使用分段机制, 我们还要求段级地址转换的结果不能超过物理地址上限:
y = seg(x) = seg.base + x < HWADDR_MAX
=> x < HWADDR_MAX - seg.base <= HWADDR_MAX
我们可以得出这样的结论: 仅仅使用分段机制, 虚拟地址是无法超过物理地址上限的. 而分页机制就不一样了, 我们无法给出 page() 具体的解析式, 是因为填写页目录和页表实际上就是在用枚举自变量的方式定义 page() 函数, 这就是分页机制比分段机制灵活的根本原因. 虽然"页级地址转换结果不能超过物理地址上限"的约束仍然存在, 但我们只要保证每一个函数值都不超过物理地址上限即可, 并没有对自变量的取值作明显的限制, 当然自变量本身也就可以比函数值还大. 这就已经把上面两点都解释清楚了.
最后我们用一张图来总结80386建立的新时代:
16 0 32 0
+--------------------+-------------------------------------+ LOGICAL
| SELECTOR | OFFSET | ADDRESS
+----+----------+----+--------------------+----------------+
+-------+ V |
| DESCRIPTOR TABLE |
| +---------------+ |
| | | |
| | | |
| | | |
| | | |
| |---------------| |
| | SEGMENT | +---+ |
+->| DESCRIPTOR |-------->| + |<----------+
|---------------| +-+-+
| | |
+---------------+ |
V PAGE FRAME
LINEAR +-----------+-----------+----------+ +---------------+
ADDRESS | DIR | PAGE | OFFSET | | |
+-----+-----+-----+-----+-----+----+ | |
| | | | |
+-------------+ | +------------->| PHYSICAL |
| | | ADDRESS |
| PAGE DIRECTORY | PAGE TABLE | |
| +---------------+ | +---------------+ | |
| | | | | | | |
| | | | | | +---------------+
| | | | |---------------| ^
| | | +-->| PG TBL ENTRY |--------------+
| |---------------| |---------------|
+->| DIR ENTRY |--+ | |
|---------------| | | |
| | | | |
+---------------+ | +---------------+
^ | ^
+-------+ | +---------------+
| CR3 |--------+
+-------+
我的妈呀, 还真够复杂的. 不过仔细看看, 你会发现这只不过是把分段和分页结合起来罢了, 用数学函数来理解, 也只不过是个复合函数:
hwaddr = page(seg(swaddr))
而"虚拟地址空间"和"物理地址空间"这两个在操作系统中无比重要的概念, 也只不过是这个复合函数的定义域和值域而已. 然而这个过程中涉及到的很多细节还是被我们忽略了. 理解80386这个新时代存在的意义和价值, 可以帮助你从更本质的角度来看待一些你在程序设计层次中感到模糊不清, 或者甚至无法解释的问题, 这也是学习这些知识的价值所在.
现代操作系统一般使用扁平模式来"绕过"IA-32分段机制. 在扁平模式中, ring 0和ring 3的段区间都是 [0, 4G) , 这意味着放在ring 0中的GDT, 页表这些重要的数据结构对于处在ring 3的恶意程序来说竟是一览无余! 扁平模式已经不能阻止恶意程序访问这些重要的数据结构了, 为何恶意程序仍然不能为所欲为?
在NEMU中实现分页机制
理解IA-32分页机制之后, 你需要在NEMU中实现它. 具体的, 你需要:
- 添加CR3寄存器.
- 为CR0寄存器添加PG位的功能. 装载CR0后, 如果发现CR0的PE位和PG位均为1, 则开启IA-32分页机制, 从此所有线性地址的访问(包括
lnaddr_read(),lnaddr_write())都需要经过页级地址转换. 在restart()函数中对CR0寄存器进行初始化时, PG位要被置0. 为了实现页级地址转换, 你需要对
lnaddr_read()和lnaddr_write()函数作少量修改. 以lnaddr_read()为例, 修改后如下:uint32_t lnaddr_read(lnaddr_t addr, size_t len) { assert(len == 1 || len == 2 || len == 4); if (data cross the page boundary) { /* this is a special case, you can handle it later. */ assert(0); } else { hwaddr_t hwaddr = page_translate(addr); return hwaddr_read(hwaddr, len); } }你需要理解页级地址转过的过程, 然后实现
page_translate()函数. 另外由于我们不打算实现保护机制, 在page_translate()函数的实现中, 你务必使用assertion检查页目录项和页表项的present位, 如果发现了一个无效的表项, 及时终止NEMU的运行, 否则调试将会异常困难. 这通常是由于你的实现错误引起的, 请检查实现的正确性. 再次提醒, 只有进入保护模式并开启分页机制之后才会进行页级地址转换.- 最后提醒一下页级地址转换时出现的一种特殊情况. 和之前实现cache的时候一样, 由于IA-32并没有严格要求数据对齐, 因此可能会出现数据跨越虚拟页边界的情况, 例如一条很长的指令的首字节在一个虚拟页的最后, 剩下的字节在另一个虚拟页的开头. 如果这两个虚拟页被映射到两个不连续的物理页, 就需要进行两次页级地址转换, 分别读出这两个物理页中需要的字节, 然后拼接起来组成一个完成的数据返回. MIPS作为一种RISC架构, 指令和数据都严格按照4字节对齐, 因此不会发生这样的情况, 否则MIPS CPU将会抛出异常, 可见软件灵活性和硬件复杂度是计算机科学中又一对tradeoff. 不过根据KISS法则, 你现在可以暂时不实现这种特殊情况的处理, 在判断出数据跨越虚拟页边界的情况之后, 先使用
assert(0)终止NEMU, 等到真的出现这种情况的时候再进行处理.
另一方面, 你需要在kernel中加入分页管理相关的代码, 你只需要在 kernel/include/common.h 中定义宏 IA32_PAGE , 然后修改 kernel/Makefile.part 中的链接选项:
上述修改让kernel的代码从虚拟地址 0xc0100000 开始(由于kernel中设定的段描述符并没有改变段级地址转换的结果, 也就是说在kenrel中, 虚拟地址和线性地址的值是一样的, 因此在描述kernel行为的时候, 我们不另外区分虚拟地址和线性地址的概念), 这样做是为了配合分页机制的加入, 更多的内容会在下文进行解释. 修改后, 重新编译kernel就可以了.
重新编译后, kernel会发生较大的变化, 现在我们来逐一解析它们. 首先是 kernel/src/start.S 的代码会有少量变化, 其中涉及到地址的部分都被 va_to_pa() 的宏进行过处理, 这是因为程序中使用的地址都是虚拟地址, 但NEMU会把kernel加载到物理地址 0x100000 处, 而在start.S中运行的时候并没有开启分页机制, 此时若直接使用虚拟地址则会发生错误.
上述文字提到了3个和内存地址相关的描述:
Makefile.part中的链接选项让kernel从虚拟地址0xc0100000开始- NEMU把kernel加载到物理地址
0x100000处 start.S中va_to_pa()的宏让地址相关的部分都减去KOFFSET
请你进一步思考, 这三者是如何相互配合, 最终让kernel成功在NEMU中运行的? 尝试分别修改其中一方(例如把 Makefile.part 中的链接选项 -Ttext 修改回 0x00100000 , 把 nemu/src/monitor/monitor.c 的 ENTRY_START 宏修改成 0x200000 , 或者把 start.S 中的 KOFFSET 宏修改成 0xc0000001 ), 编译后重新运行, 并思考为什么修改后kernel会运行失败.
kernel最大的变化在C代码中. 跳转到 init() 函数之后, 第一件事就是为kernel自己创建虚拟地址空间, 并开启分页机制. 这是通过 init_page() 函数(在 kernel/src/memory/kvm.c 中定义)完成的, 具体的工作有:
- 填写页目录项和页表项
- 将页目录基地址装载到CR3寄存器
- 将CR0的PG位置1, 开启分页机制
结合kernel的框架代码理解分页机制 阅读 init_page() 函数的代码, 它建立了一个从虚拟地址到物理地址的映射. 请结合此处代码描述这个映射具体是怎么样的, 并尝试画出这个映射: 画两个矩形, 左边代表虚拟地址, 右边代表物理地址, 并标上0和4G, 然后画出哪一段虚拟地址对应哪一段物理地址. 你可以先用纸笔来画, 然后拍照片, 把照片插入到实验报告中.
开启分页机制后, kernel就可以使用虚拟地址了. 接下来kernel的初始化工作如下:
- 首先让
%esp加上KOFFSET转化成相应的虚拟地址, 然后通过间接跳转进入init_cond()函数继续进行初始化, 这样kernel就完全工作在虚拟地址中了. - 使用
Log()宏输出一句话, 同样地, 现在的Log()宏还是不能成功输出. - 初始化MM. 这里的MM是指存储管理器(Memory Manager)模块, 它专门负责和用户进程分页相关的存储管理. 目前初始化MM的工作就是初始化用户进程的页目录, 同时将用户进程在
0xc0000000以上的虚拟地址映射到和kernel一样的物理地址.
在 loader() 函数中加载ELF可执行文件是另一个需要理解的难点. 由于我们开启了分页机制, 将来用户进程将运行在分页机制之上, 这意味着用户进程使用的地址都是虚拟地址, kernel要先为用户进程创建虚拟地址空间. 因此我们就可以为用户进程提供更方便的运行时环境了:
- 代码和数据位于
0x8048000附近. - 有自己的虚拟地址空间, 最大是4GB, 不过这需要kernel实现交换技术. 虽然我们不打算实现交换技术, 但"虚拟地址作为物理地址的抽象"这一好处已经体现出来了: 原则上用户程序可以运行在任意的虚拟地址, 不受物理内存容量的限制. 我们让程序的代码从
0x8048000附近开始, 这个地址已经超过了物理地址的最大值(NEMU提供的物理内存是128MB), 但分页机制保证了程序能够正确运行. 这样, 链接器和程序都不需要关心程序运行时刻具体使用哪一段物理地址, 它们只要使用虚拟地址就可以了, 而虚拟地址和物理地址之间的映射则全部交给kernel的MM来管理. %ebp的初值为0,%esp的初值为0xc0000000, 堆栈大小为1MB.- 程序通过
nemu_trap结束运行. - 提供uclibc库函数的静态链接
这一运行时环境规定的进程地址空间和GNU/Linux十分相似, 我们可以不显式指定用户程序链接参数中的代码段位置, 链接器会默认将代码段放置在 0x8048000 附近:
为了向用户进程提供这一升级版的运行时环境, 你需要对加载过程作少量修改. 此时program header中的 p_vaddr 就真的是用户进程的虚拟地址了, 但它并不在kernel的虚拟地址空间中, 所以kernel不能直接访问它. kernel要做的事情就是:
- 按照program header中的
p_memsz属性, 为这一段segment分配一段不小于p_memsz的物理内存 - 根据虚拟地址
p_vaddr和分配到的物理地址正确填写用户进程的页目录和页表 - 把ELF文件中的segment的内容加载到这段物理内存
这一切都是为了让用户进程在将来可以正确地运行: 用户进程在将来使用虚拟地址访问内存, 在kernel为用户进程填写的页目录和页表的映射下, 虚拟地址被转换成物理地址, 通过这一物理地址访问到的物理内存, 恰好就是用户进程想要访问的数据. 物理内存并不是可以随意分配的, 如果把kernel正在使用的物理页分配给用户进程, 将会发生致命的错误. NEMU模拟的物理内存只有128MB, 我们约定低16MB的空间专门给kernel使用, 剩下的112MB供用户进程使用, 即第一个可分配给用户进程的物理页首地址是 0x1000000 .
不过这一部分的内容实现起来会涉及很多细节问题, 出现错误是十有八九的事情. 为了减轻大家的负担, 我们已经为大家准备了一个内存分配的接口函数 mm_malloc() , 其函数原型为:
它的功能是为用户进程分配一段以虚拟地址 va 开始, 长度为 len 的连续的物理内存区间, 并填写为用户进程准备的页目录和页表, 然后返回这一段物理内存区间的首地址. 由于 mm_malloc() 的实现和操作系统实验有关, 我们没有提供 mm_malloc() 函数的源代码, 而是提供了相应的目标文件 mm_malloc.o , Makefile 中已经设置好相应的链接命令了, 你可以在 loader() 函数中直接调用它, 完成上述内存分配的功能. 你不必为此感到沮丧, 我们已经为你准备了另外一个简单的分页小练习(见下文). 有兴趣的同学可以尝试编写自己的 mm_malloc() 函数, 也可以尝试通过 mm_malloc.o 破解相应的源代码.
分配连续的物理页面是一个很强的要求, 当操作系统运行了一段时间, 并且运行的程序较多时, 空闲的物理页面会分布得十分零散, "分配一段很大的连续物理区间"这一要求通常很难被满足. 如果 mm_malloc() 允许分配不连续的物理页面, 你编写的 loader() 函数还能正确地加载程序吗? 思考一下可能会出现什么问题? 应该如何解决它?
加载ELF可执行文件之后, kernel还会为用户进程分配堆栈, 堆栈从虚拟地址 0xc0000000 往下生长, 大小为1MB. 这样用户进程的地址空间就创建好了, 更新CR3后, 此时kernel已经运行在刚刚创建好的地址空间上了. 接下来做的事情和之前差不多:
loader()将返回用户程序的入口地址.- 把
%esp设置成0xc0000000. - 跳转到用户程序的入口执行.
此时用户进程已经完全运行在分页机制上了.
根据上述的讲义内容, 在NEMU中模拟IA-32分页机制, 如有疑问, 请查阅i386手册. 在 lib-common/x86-inc 目录下的头文件中定义了一些和x86相关的宏和结构体, 你可以在NEMU中包含这些头文件来使用它们.
为了方便调试, 你可以在monitor中添加如下命令:
page ADDR
这条命令的功能是输出地址 ADDR 的页级地址转换结果, 当地址转换失败时, 输出失败信息. 你可以根据你的实际需要添加或更改这条命令的功能.
在 kernel/src/memory/kvm.c 中, 为了提高效率, 我们使用了内联汇编来填写页表项, 同时给出了相应的C代码作为参考. 如果你曾经尝试用C代码替换内联汇编, 编译后重新运行, 你会看到发生了错误. 事实上, 作为参考的C代码中隐藏着一个小小的bug, 这个bug的藏身之术十分高超, 以至于几乎不影响你对C代码的理解. 聪明的你能够让这个嚣张的bug原形毕露吗?
这一部分的内容算是整个PA中最难理解的了, 其中涉及到很多课本上没有提到的细节. 不过上文的讨论还是忽略了很多细节的问题, 分页机制中也总是暗藏杀机, 如果你喜欢一些挑战性的工作, 你可以在完成这一部分的实验内容之后尝试完成下面的蓝框题. 当你把这些问题都弄明白之后, 你就不会再害怕由于分页机制而造成的错误了.
尝试回答下列问题之前, 你需要保证你的分页机制实现正确, 用户进程可以在你实现的分页机制上运行. 否则一些问题的原因可能会被你造成的错误所掩盖, 会让你百思不得其解.
- 在
init()函数中有一处注释"Before setting up correct paging, no global variable can be used". 尝试在main.c中定义一个全局变量, 然后在调用init_page()前使用这个全局变量:
--- kernel/src/main.c
+++ kernel/src/main.c
@@ -19,9 +19,11 @@
+volatile int x = 0;
/* Initialization phase 1
* The assembly code in start.S will finally jump here.
*/
void init() {
#ifdef IA32_PAGE
+ x = 1;
/* We must set up kernel virtual memory first because our kernel thinks it
* is located at 0xc0100000, which is set by the linking options in Makefile.
* Before setting up correct paging, no global variable can be used. */
init_page();
重新编译并运行, 你发现了什么问题? 请解释为什么在开启分页之前不能使用全局变量, 但却可以使用局部变量(在 init_page() 函数中使用了局部变量). 细心的你会发现, 在开启分页机制之前, init_page() 中仍然使用了一些全局变量, 但却没有造成错误, 这又是为什么?
- 在刚刚调用
init_page()的时候, 分页机制并没有开启. 但通过objdump查看kernel的代码, 你会发现init_page()函数在0xc0000000以上的地址, 为什么在没有开启分页机制的情况下调用位于高地址的init_page()却不会发生错误? - 你已经画出
init_page()函数中创建的映射了, 这个映射把两处虚拟地址映射到同一处物理地址, 请解释为什么要创建这样一个映射. 具体地, 在init_page()的循环中有这样两行代码:
pdir[pdir_idx].val = make_pde(ptable);
pdir[pdir_idx + KOFFSET / PT_SIZE].val = make_pde(ptable);
尝试注释掉其中一行, 重新编译kernel并运行, 你会看到发生了错误. 请解释这个错误具体是怎么发生的.
- 在
init()函数中, 我们通过内联汇编把%esp加上KOFFSET转化成相应的虚拟地址. 尝试把这行内联汇编注释掉, 重新编译kernel并运行, 你会看到发生了错误. 请解释这个错误具体是怎么发生的. - 在
init()函数中, 我们通过内联汇编间接跳转到init_cond()函数. 尝试把这行内联汇编注释掉, 改成通过一般的函数调用来跳转到init_cond()函数, 重新编译kernel并运行, 你会看到发生了错误. 请解释这个错误具体是怎么发生的. - 在
init_mm()函数中, 有一处代码用于拷贝0xc0000000以上的内核映射:
/* create the same mapping above 0xc0000000 as the kernel mapping does */
memcpy(&updir[KOFFSET / PT_SIZE], &kpdir[KOFFSET / PT_SIZE],
(PHY_MEM / PT_SIZE) * sizeof(PDE));
尝试注释这处代码, 重新编译kernel并运行, 你会看到发生了错误. 请解释这个错误具体是怎么发生的.
video memory是一段有特殊功能的内存区间, 我们会在PA4中作进一步解释. 在 loader() 函数中有一处代码会调用 create_video_mapping() 函数(在 kernel/src/memory/vmem.c 中定义), 为用户进程创建video memory的恒等映射, 即把从 0xa0000 开始, 长度为 320 * 200 字节的虚拟内存区间映射到从 0xa0000 开始, 长度为 320 * 200 字节的物理内存区间. 有兴趣的同学可以实现 create_video_mapping() 函数, 具体的, 你需要定义一些页表(注意页表需要按页对齐, 你可以参考 kernel/src/memory/kvm.c 中的相关内容), 然后填写相应的页目录项和页表项即可. 注意你不能使用 mm_malloc() 來实现video memory映射的创建, 因为 mm_malloc() 分配的物理页面都在16MB以上, 而video memory位于16MB以内, 故使用 mm_malloc() 不能达到我们的目的.
实现完成后, 让kernel调用 video_mapping_write_test() , video_mapping_read_test() 和 video_mapping_clear() (把相应的函数调用移出条件编译块即可), 这些代码会在为用户进程创建地址空间之前向video memory写入一些测试数据, 创建地址空间之后读出这些数据并检查. 如果你的 create_video_mapping() 实现有问题, 你将不能通过检查.
这个video memory的映射将会在PA4中用到, 现在算是一个简单的分页小练习, 帮助你更好地理解IA-32分页机制. 你现在可以选择忽略这个问题, 但你会在PA4中重新面对它.
PA3阶段3到此结束.
近水楼台先得月(2)
细心的你会发现, 在不改变CR3, 页目录和页表的情况下, 如果连续访问同一个虚拟页的内容, 页级地址转换的结果都是一样的. 事实上, 这种情况太常见了, 例如程序执行的时候需要取指令, 而指令的执行一般都遵循局部性原理, 大多数情况下都在同一个虚拟页中执行. 但进行page walk是要访问内存的, 如果有方法可以避免这些没有必要的page walk, 就可以提高处理器的性能了.
一个很自然的想法就是将页级地址转换的结果存起来, 在进行下一次的页级地址转换之前, 看看这个虚拟页是不是已经转换过了, 如果是, 就直接取出之前的结果, 这样就可以节省不必要的page walk了. 这不正好是cache的思想吗? 于是80386加入了一个特殊的cache, 叫TLB. 我们可以从CPU cache的知识来理解TLB的组织:
- TLB的基本单元是项, 一项存放了一次页级地址转换的结果(其实就是一个页表项, 包括物理页号和一些和物理页相关的标志位), 功能上相当于一个cache block.
- TLB项的tag由虚拟页号(即线性地址的高20位)来充当, 表示这一项对应于哪一个虚拟页号.
- TLB的项数一般不多, 为了提高命中率, TLB一般采用fully associative的组织方式.
- 由于页目录和页表一旦建立之后, 一般不会随意修改其中的表项, 因此TLB不存在写策略和写分配方式的问题.
实践表明, 大小64项的TLB, 命中率可以高达90%, 有了TLB之后, 果然大大节省了不必要的page walk.
听上去真不错! 不过在现代的多任务操作系统中, 如果仅仅简单按照上述方式来使用TLB, 却会导致致命的后果. 我们知道, 现在的计算机可以"同时"运行多个进程, 这里的"同时"其实只是一种假象, 并不是指在物理时间上的重叠, 而是操作系统很快地在不同的进程之间来回切换, 切换的频率大约是10ms一次, 一般的用户是感觉不到的. 而让多个进程"同时"运行的一个基本条件, 就是不同的进程要拥有独立的存储空间, 它们之间不能相互干扰. 这一条件是通过分页机制来保证的, 操作系统为每个进程分配不同的页目录和页表, 虽然两个进程可能都会从 0x8048000 开始执行, 但分页机制会把它们映射到不同的物理页, 从而做到存储空间的隔离. 当然, 操作系统进行进程切换的时候也需要更新CR3的内容, 使得CR3寄存器指向新进程的页目录, 这样才能保证分页机制将虚拟地址映射到新进程的物理存储空间.
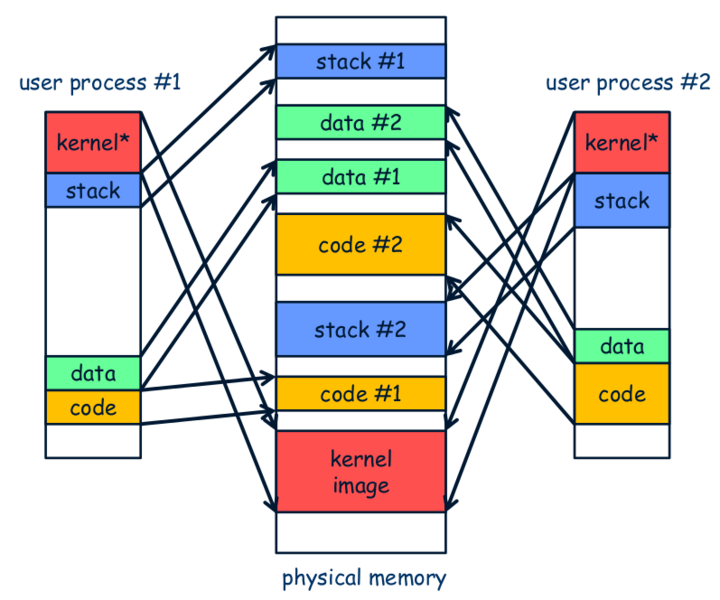
现在问题来了, 假设有两个进程, 对于同一个虚拟地址 0x8048000 , 操作系统已经设置好正确的页目录和页表, 让1号进程映射到物理地址 0x1234000 , 2号进程映射到物理地址 0x5678000 , 同时假设TLB一开始所有项都被置为无效. 这时1号进程先运行, 访问虚拟地址 0x8048000 , 查看TLB发现未命中, 于是进行page walk, 根据1号进程的页目录和页表进行页级地址转换, 得到物理地址 0x1234000 , 并填充TLB. 假设此时发生了进程切换, 轮到2号进程来执行, 它也要访问虚拟地址 0x8048000 , 查看TLB, 发现命中, 于是不进行page walk, 而是直接使用TLB中的物理页号, 得到物理地址 0x1234000 . 2号进程竟然访问了1号进程的存储空间, 但2号进程和操作系统对此都毫不知情!
出现这个致命错误的原因是, TLB没有维护好进程和虚拟地址映射关系的一致性, TLB只知道有一个从虚拟地址 0x8048000 到物理地址 0x1234000 的映射关系, 但它并不知道这个映射关系是属于哪一个进程的. 找到问题的原因之后, 解决它也就很容易了, 只要在TLB项中增加一个域ASID(address space ID), 用于指示映射关系所属的进程即可, MIPS就是这样做的. IA-32的做法则比较"野蛮", 在每次更新CR3时强制冲刷TLB的内容, 由于进程切换必定伴随着CR3的更新, 因此一个进程运行的时候, TLB中不会存在其它进程的映射关系.
在NEMU中实现一个TLB, 它的性质如下:
- TLB总共有64项
- fully associative
- 标志位只需要valid bit即可
- 替换算法采用随机方式
你还需要在 restart() 函数中对TLB进行初始化, 将所有valid bit置为无效即可. 在 page_translate() 的实现中, 先查看TLB, 如果命中, 则不需要进行page walk; 如果未命中, 则需要进行page walk, 并填充TLB. 另外不要忘记, 更新CR3的时候需要强制冲刷TLB中的内容. 由于TLB对程序来说是透明的, 所以kernel不需要为TLB的功能添加新的代码.
最后我们来聊聊cache和虚拟存储的关系. 课堂上我们提到的cache都是用物理地址来查找的, 引入虚拟存储的概念之后, 原则上我们也可以使用虚拟地址来查找. 从这个角度来考虑, 我们可以组合出4种cache:
- physical index, physical tag(PIPT)
- physical index, virtual tag(PIVT)
- virtual index, physical tag(VIPT)
- virtual index, virtual tag(VIVT)
其中PIPT就是我们在课堂上提到的情况, 用物理地址的中间部分作为index找到一个或若干个cache block, 然后用物理地址的高位部分作为tag检查是否匹配, 不过这要求每一次cache查找之前都需要经过地址转换. 但PIPT实现起来最简单, 其实你也已经实现PIPT了, 因此你不需要对代码作额外的改动. 而VIVT则可以先查找cache, 如果cache命中, 就不需要进行地址转换了, 可以直接取出数据. 不过VIVT和TLB一样, 需要维护进程和虚拟地址的一致性, 同时还有可能产生别名(aliasing)问题: 如果多个虚拟地址被映射到同一个物理地址, 就有可能造成物理上的一份数据以多个不同虚拟地址的拷贝存放在cache中, 这时如果对其中某一份拷贝进行写操作, 就要维护好这几份不同拷贝的数据一致性.
尝试根据cache和虚拟存储的知识, 分析PIVT和VIPT的性能和局限性. 特别地, 如果要在IA-32中实现一个VIPT cache, cache的组织方式有什么限制吗?