分时多任务
多道程序成功地实现了任务的并发执行, 但这种并发不一定是公平的. 如果一个进程长时间不触发I/O操作, 多道程序系统并不会主动将控制权切换到其它进程, 这样其它进程就得不到运行的机会. 想象一下, 如果你在开黑的时候, Windows突然在后台进行自动更新, 队友就打电话问你怎么老掉线, 你一定会非常不爽. 所以多道程序系统更多还是用在批处理的场景当中, 它能保证CPU满负荷运转, 但并不适合用于交互式的场景.
如果要用于交互式场景, 系统就要以一定的频率在所有进程之间来回切换,
保证每个进程都能及时得到响应, 这就是分时多任务.
从触发上下文切换的角度看, 分时多任务可以分成两类.
第一类是协同多任务, 它的工作方式基于一个约定:
用户进程周期性地主动让出CPU的控制权, 从而让其它进程得到运行的机会.
这件事需要操作系统提供一个特殊的系统调用, 那就是我们在PA3中实现的SYS_yield.
在PA3中看似没什么用的SYS_yield, 其实是协同多任务操作系统中上下文切换的基石.
说是"协同", 是因为这个机制需要所有进程一起合作,
共同遵守这个约定, 整个系统才能正确工作.
一些简单的嵌入式操作系统或者实时操作系统会采用协同多任务,
因为这些系统上运行的程序都是固定的那么几个,
让它们共同遵守约定来让出CPU并不困难.
但试想一下, 在多用户操作系统中, 运行程序的来源是无法预知的,
如果有一个恶意进程故意不遵守这个约定, 不调用SYS_yield,
或者无意陷入了死循环, 整个系统将会被这个进程独占.
上古时期的某些Windows版本就采用了协同多任务的设计,
操作系统经常会被一些有bug的程序弄垮.
之所以协同多任务会出现这样的问题, 是系统将上下文切换的触发条件寄托在进程的行为之上. 我们知道调度一个进程的时候, 整个计算机都会被它所控制, 无论是计算, 访存, 还是输入输出, 都是由进程的行为来决定的. 为了修复这个漏洞, 我们必须寻找一种无法由进程控制的机制.
来自外部的声音
回想起我们考试的时候, 在试卷上如何作答都是我们来控制的, 但等到铃声一响, 无论我们是否完成答题, 都要立即上交试卷. 我们希望的恰恰就是这样一种效果: 时间一到, 无论正在运行的进程有多不情愿, 操作系统都要进行上下文切换. 而解决问题的关键, 就是时钟. 我们在IOE中早就已经加入了时钟了, 然而这还不能满足我们的需求, 我们希望时钟能够主动地通知处理器, 而不是被动地等着处理器来访问.
这样的通知机制, 在计算机中称为硬件中断. 硬件中断的实质是一个数字信号, 当设备有事件需要通知CPU的时候, 就会发出中断信号. 这个信号最终会传到CPU中, 引起CPU的注意.
第一个问题就是中断信号是怎么传到CPU中的. 支持中断机制的设备控制器都有一个中断引脚, 这个引脚会和CPU的INTR引脚相连, 当设备需要发出中断请求的时候, 它只要将中断引脚置为高电平, 中断信号就会一直传到CPU的INTR引脚中. 但计算机上通常有多个设备, 而CPU引脚是在制造的时候就固定了, 因而在CPU端为每一个设备中断分配一个引脚的做法是不现实的.
为了更好地管理各种设备的中断请求, IBM PC兼容机中都会带有Intel 8259 PIC(Programmable Interrupt Controller, 可编程中断控制器), 而RISC-V系统中用得比较多的中断控制器则是PLIC(Platform Level Interrupt Controller). 中断控制器最主要的作用就是充当设备中断信号的多路复用器, 即在多个设备中断信号中选择其中一个信号, 然后转发给CPU.
第二个问题是CPU如何响应到来的中断请求. CPU每次执行完一条指令的时候, 都会看看INTR引脚, 看是否有设备的中断请求到来. 一个例外的情况就是CPU处于关中断状态, 此时即使INTR引脚为高电平, CPU也不会响应中断. CPU的关中断状态和中断控制器是独立的, 中断控制器只负责转发设备的中断请求, 最终CPU是否响应中断还需要由CPU的状态决定.
CPU的关中断状态可以通过软件来控制, 不同的ISA对此有不同的定义, 具体地:
- 在x86中, 如果EFLAGS中的IF位为0, 则CPU处于关中断状态
- 在mips32中, 如果status中的IE位为0, 或EXL位为1, 或ERL位为1, 则CPU处于关中断状态
- 在riscv32中, 如果mstatus中的MIE位为0, 则CPU处于关中断状态
- 事实上, riscv32标准的中断响应机制还有更多内容, 在PA中我们进行了简化. 如需了解完整的中断响应机制, 请查阅相关手册.
如果中断到来的时候, CPU没有处在关中断状态, 它就要马上响应到来的中断请求. 我们刚才提到中断控制器会生成一个中断号, CPU将会保存中断上下文, 然后把这个中断作为异常处理过程的原因, 找到并跳转到入口地址, 进行一些和设备相关的处理. 这个过程和之前提到的异常处理十分相似.
对CPU来说, 设备的中断请求何时到来是不可预测的, 在处理一个中断请求的时候到来了另一个中断请求也是有可能的. 如果希望支持中断嵌套 -- 即在进行优先级低的中断处理的过程中, 响应另一个优先级高的中断 -- 那么堆栈将是保存中断上下文信息的唯一选择. 如果选择把上下文信息保存在一个固定的地方, 发生中断嵌套的时候, 第一次中断保存的上下文信息将会被优先级高的中断处理过程所覆盖, 从而造成灾难性的后果.
灾难性的后果(这个问题有点难度)
假设硬件把中断信息固定保存在某个内存地址(例如0x1000)的位置, AM也总是从这里开始构造上下文.
如果发生了中断嵌套, 将会发生什么样的灾难性后果?
这一灾难性的后果将会以什么样的形式表现出来?
如果你觉得毫无头绪, 你可以用纸笔模拟中断处理的过程.
如何支持中断嵌套
思考一下, x86, mips32和riscv32的软硬件该分别如何协同, 来支持中断嵌套?
抢占多任务
分时多任务的第二类就是抢占多任务, 它基于硬件中断(通常是时钟中断)强行进行上下文切换, 让系统中的所有进程公平地轮流运行. 在抢占多任务操作系统中, 中断是其赖以生存的根基: 只要中断的东风一刮, 操作系统就会卷土重来, 一个故意死循环的恶意程序就算有天大的本事, 此时此刻也要被请出CPU, 从而让其它程序得到运行的机会,
在NEMU中, 我们只需要添加时钟中断这一种中断就可以了.
由于只有一种中断, 我们也不需要通过中断控制器进行中断的管理,
直接让时钟中断连接到CPU的INTR引脚即可.
而对于时钟中断的中断号, 不同的ISA有不同的约定.
时钟中断通过nemu/src/device/timer.c中的timer_intr()触发, 每10ms触发一次.
触发后, 会调用dev_raise_intr()函数(在nemu/src/device/intr.c中定义).
你需要:
- 在cpu结构体中添加一个
bool成员INTR. - 在
dev_raise_intr()中将INTR引脚设置为高电平. - 在
cpu_exec()中for循环的末尾添加轮询INTR引脚的代码, 每次执行完一条指令就查看是否有硬件中断到来:word_t intr = isa_query_intr(); if (intr != INTR_EMPTY) { cpu.pc = isa_raise_intr(intr, cpu.pc); } - 实现
isa_query_intr()函数(在nemu/src/isa/$ISA/system/intr.c中定义):
#define IRQ_TIMER 32 // for x86
#define IRQ_TIMER 0 // for mips32
#define IRQ_TIMER 0x80000007 // for riscv32
#define IRQ_TIMER 0x8000000000000007 // for riscv64
word_t isa_query_intr() {
if ( ??? ) {
cpu.INTR = false;
return IRQ_TIMER;
}
return INTR_EMPTY;
}
- 修改
isa_raise_intr()中的代码, 让处理器进入关中断状态:- x86 - 在保存EFLAGS寄存器后, 将其IF位置为
0 - mips32 - 将status.EXL位置为
1- 你还需要修改eret指令的实现, 将status.EXL置为
0
- 你还需要修改eret指令的实现, 将status.EXL置为
- riscv32 - 将mstatus.MIE保存到mstatus.MPIE中, 然后将mstatus.MIE位置为
0- 你还需要修改mret指令的实现, 将mstatus.MPIE还原到mstatus.MIE中, 然后将mstatus.MPIE位置为
1
- 你还需要修改mret指令的实现, 将mstatus.MPIE还原到mstatus.MIE中, 然后将mstatus.MPIE位置为
- x86 - 在保存EFLAGS寄存器后, 将其IF位置为
在软件上, 你还需要:
- 在CTE中添加时钟中断的支持, 将时钟中断打包成
EVENT_IRQ_TIMER事件. - Nanos-lite收到
EVENT_IRQ_TIMER事件之后, 调用schedule()来强制当前进程让出CPU, 同时也可以去掉我们之前在设备访问中插入的yield()了. - 为了可以让处理器在运行用户进程的时候响应时钟中断, 你还需要修改
kcontext()和ucontext()的代码, 在构造上下文的时候, 设置正确中断状态, 使得将来恢复上下文之后CPU处于开中断状态.
实现抢占多任务
根据讲义的上述内容, 添加相应的代码来实现抢占式的分时多任务.
为了测试时钟中断确实在工作, 你可以在Nanos-lite收到EVENT_IRQ_TIMER事件后用Log()输出一句话.
硬件中断与DiffTest
对DiffTest来说, 我们无法直接给QEMU注入时钟中断, 从而无法保证在中断到来时QEMU与NEMU处于相同的状态. 不过, 伴你一路走来的基础设施, 相信也已经帮你排除了绝大部分的bug了, 接下来的一小段路就试试靠自己吧.
中断和用户进程初始化
我们知道, 用户进程从Navy的_start开始运行, 并且在_start中设置正确的栈指针.
如果在用户进程设置正确的栈指针之前就到来了中断,
我们的系统还能够正确地进行中断处理吗?
基于时间片的进程调度
在抢占多任务操作系统中, 由于时钟中断以固定的速率到来, 时间被划分成长度均等的时间片, 这样系统就可以进行基于时间片的进程调度了.
优先级调度
我们可以修改schedule()的代码, 给仙剑奇侠传分配更多的时间片,
使得仙剑奇侠传调度若干次, 才让hello内核线程调度1次.
这是因为hello内核线程做的事情只是不断地输出字符串,
我们只需要让hello内核线程偶尔进行输出, 以确认它还在运行就可以了.
我们会发现, 给仙剑奇侠传分配更多的时间片之后, 其运行速度有了一定的提升. 这再次向我们展现了"分时"的本质: 程序之间只是轮流使用处理器, 它们并不是真正意义上的"同时"运行.
真实系统中的调度问题比上面仙剑奇侠传的例子要复杂得多. 比如双十一节, 全国一瞬间向阿里巴巴的服务器发起购物请求, 这些请求最终会被转化成上亿个进程在成千上万台服务器中被处理. 在数据中心中如何调度数量如此巨大的进程, 来尽可能提高用户的服务质量, 是阿里巴巴一直都面临的严峻挑战.
抢占和并发
如果没有中断的存在, 计算机的运行就是完全确定的. 根据计算机的当前状态, 你完全可以推断出下一条指令执行后, 甚至是执行100条指令后计算机的状态. 但如果让计算机支持中断, 状态机的行为就变得难以预测了.
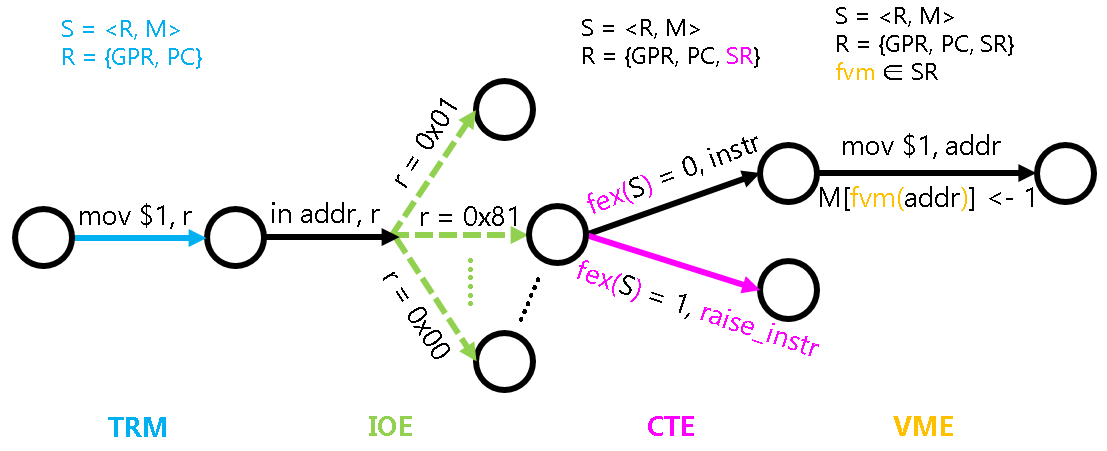
为了对中断的行为进行建模, 我们对fex()函数的定义进行扩展:
除了判断当前状态是否需要抛出异常, 如果当前处理器处于开中断状态, 还需要判断是否有中断到来.
这说明在每条指令执行的时候, 计算机都将有可能因为中断到来而跳转到中断处理函数.
中断给计算机系统带来的不确定性可以说是一把双刃剑.
比如GNU/Linux内核会维护一个entropy pool, 用于收集系统中的熵(不确定性).
每当中断到来的时候, 就会给这个pool添加一些熵.
通过这些熵, 我们就可以生成真正的随机数了, /dev/random就是这样做的.
有了真正的随机数, 恶意程序的攻击也变得相对困难了(比如ASLR), 系统的安全也多了一分保障.
但另一方面, 中断的存在也不得不让程序在一些问题的处理上需要付出额外的代价.
由于中断随时可能会到来, 如果两个进程有一个共享的变量v(比如迅雷多线程下载共享同一个文件缓冲区),
一个进程A往v中写0, 刚写完中断就到来,
但当下次A再次运行的时候, v的值就可能不再是0了.
从某种程度上来说, 这也是并发惹的祸: 可能进程B在并发地修改v的值, 但A却不知情.
这种由于并发造成的bug, 还带有不确定性的烙印: 如果中断到来的时机不一样, 就不会触发这个bug了.
所以这种bug又叫Heisenbug, 和量子力学的测不准原理类似,
你想调试它的时候, 它可能就不出现了.
不但是用户进程之间可能会有共享变量, 操作系统内核更是并发bug的重灾区. 比如并发写同一个文件的多个用户进程会共享同一个文件偏移量, 如果处理不当, 可能就会导致写数据丢失. 更一般地, 用户进程都会并发地执行系统调用, 操作系统还需要保证它们都能按照系统调用的语义正确地执行.
啊, 还是不剧透那么多了, 大家到了操作系统课再慢慢体(xiang)会(shou)乐(tong)趣(ku)吧, 也许到时候你就会想念PA单线程的好了.
内核栈和用户栈
我们之前把如下问题作为最难的思考题留给大家思考:
为什么目前不支持并发执行多个用户进程?
现在我们就来揭晓问题的答案: 这是因为用户栈的访问造成的.
问题分析
为了方便描述, 我们假设某一时刻, 操作系统将要从用户进程A切换到用户进程B.
具体地, 在A运行的时候, 栈指针sp会指向A的用户栈.
当A执行系统调用, 或者中断到来的时候, 就会经过CTE陷入操作系统.
注意到这时CTE是在A的用户栈上保存A的上下文, 而sp也仍然指向A的用户栈.
这时, 操作系统决定要调度用户进程B, 它就会把B的上下文返回给CTE,
CTE会依次进行如下操作:
- 通过
__am_switch()切换到B的虚拟地址空间 - 在
trap.S中恢复B的上下文
现在问题来了: A的用户栈并不在B的虚拟地址空间里面!
这意味着, 当__am_switch()切换到B的虚拟地址空间之后, 代码就不能再访问A的用户栈了:
所有和sp相关的访存都会被分页机制映射到B的用户栈中.
于是在__am_switch()到trap.S恢复B的上下文的这段时间里面, 代码都无法正确地访问栈:
从函数返回时就会跳转到错误的位置, 而写一个局部变量就会覆盖B的用户栈中的内容...
为了解决这个问题, 一种方案是让切换虚拟地址空间的操作和上下文恢复的操作同时进行. x86的TSS(Task State Segment)机制就是采用这种方案, 它要求系统软件(例如操作系统)先在内存中准备一个用于描述进程上下文的特殊结构体, 结构体中还包括用于描述进程虚拟地址空间的CR3寄存器的值, 然后把结构体的地址信息设置到一个叫TR的系统寄存器中, 最后执行一条特殊的指令, 硬件就会根据结构体中的内容自动地恢复上下文并切换虚拟地址空间. 这种方案需要在硬件上实现一条行为非常复杂的上下文恢复指令, 显然不是所有架构的处理器都有这样的指令.
Linux的上下文切换
在Linux的早期版本, 上下文切换正是通过TSS的硬件机制来进行的. 后来大家发现, 在硬件上实现这条复杂的指令, 性能还比不上软件实现的上下文切换. 加上随着Linux版本的演进, 更多的架构需要加入进来, 为了更好地维护代码, Linux最后还是选择了软件实现的上下文切换. 这篇文章总结了Linux上下文切换部分的代码从最初的0.01版本到现代的4.x版本的演进过程, 供有兴趣的同学进行了解.
第二种方案是将切换虚拟地址空间的指令和恢复上下文的指令尽可能靠近, 并保证其中没有任何访问栈的操作. 在一些全局变量的帮助下, 这个方案是可以做到的, 但现代的操作系统都不采用这个方案, 这是因为在用户栈上保存上下文这个做法是有安全漏洞的. 一个恶意程序可以执行如下的指令序列:
la sp, kernel_addr
ecall
如果操作系统把上下文保存到sp所指向的内存位置,
位于kernel_addr的内核数据将会受到恶意破坏!
为了避免上述问题, 现代的操作系统一般会采取第三个方案. 操作系统需要准备一个自己的栈: 操作系统不能相信陷入内核时栈指针的值, 在进行任何栈操作之前(包括保存上下文), 操作系统都需要先把栈指针指向自己准备的栈. 这个栈就是我们之前介绍的内核栈.
撇开安全漏洞的话题不谈, 使用内核栈还可以使得上述"用户栈与虚拟地址空间不一致"不攻自破: 内核栈位于内核的虚拟地址空间之内, 而所有虚拟地址空间都会包含内核映射, 这保证了无论操作系统切换到哪一个虚拟地址空间, 代码都可以成功访问内核栈.
栈切换的概念细节
因此我们需要实现如下功能:
- 如果是从用户态进入CTE, 则在CTE保存上下文之前, 先切换到内核栈, 然后再保存上下文
- 如果将来返回到用户态, 则在CTE从内核栈恢复上下文之后, 则先切换到用户栈, 然后再返回
注意如果我们是从内核态进入CTE, 则无需切换; 若此时我们错误地将栈指针再次指向内核栈的底部, 内核栈的已有内容将会被接下来的压栈操作所覆盖!
用户态和栈指针
一般来说, 处理器的特权级也是一种状态. 我们是否可以通过栈指针的值来判断当前位于用户态还是内核态?
基本功能
而为了实现上述功能, 我们又需要解决如下问题:
- 如何识别进入CTE之前处于用户态还是内核态? -
pp(Previous Privilege) - CTE的代码如何知道内核栈在什么位置? -
ksp(Kernel Stack Pointer) - 如何知道将要返回的是用户态还是内核态? -
np(Next Privilege) - CTE的代码如何知道用户栈在什么位置? -
usp(User Stack Pointer)
我们为每一个问题分别定义了一个概念变量, 要解决这些问题, 就是要在CTE中正确地维护这些变量.
我们用伪代码来描述需要实现的功能, 其中$sp表示栈指针寄存器:
void __am_asm_trap() {
if (pp == USER) {
usp = $sp;
$sp = ksp;
}
np = pp;
// save context
__am_irq_handle(c);
// restore context
pp = np;
if (np == USER) {
ksp = $sp;
$sp = usp;
}
return_from_trap();
}
注意上述伪代码只是描述概念上的行为, 并不代表代码也要严格按照相应的顺序来编写,
例如np = pp;可以放在保存上下文之后, 甚至是在__am_irq_handle()的开头来进行.
从伪代码上看, 我们需要添加的功能并不复杂.
系统的复杂性
如果你觉得上述代码不难实现, 你就太小看系统的复杂性了. 尝试先不阅读下面的内容, 分析一下上述代码在实际的运行过程中可能会出现什么问题? 如果出现问题, 应该如何解决它们?
上下文切换
但是不要忘记, 操作系统可能会通过CTE返回一个新的上下文结构并进行切换, 我们需要保证代码在上下文切换会发生的条件下仍然可以正确工作,
系统的复杂性(2)
既然你已经看到这里了, 也尝试先不阅读下面的内容, 然后尝试分析一下, 应该如何保证代码在上下文切换会发生的条件下仍然可以正确工作?
我们需要仔细考量上述变量的行为.
经过一些简单的分析, 我们可以发现, pp和ksp并不会受到上下文切换的影响:
它们在离开CTE之前被赋值, 但是在下一次进入CTE的时候才会被使用,
期间它们的值不会改变, 而上下文切换只会在它们被使用之后才会发生.
但np和usp就不一样了, 它们在进入CTE的时候被赋值, 在离开CTE之前被使用,
而期间可能会发生上下文切换.
我们很容易就可以构造出一个例子来展示上下文切换带来的问题.
假设某用户进程因为系统调用或中断到来进入CTE, 上述代码会把np设置为USER,
表示下一次离开CTE的时候将要返回用户态.
如果在这期间发生了上下文切换, 切换到了一个内核线程,
内核线程在恢复上下文之后查看np, 发现是USER, 就会错误地把usp设置到$sp,
我们知道内核线程并没有用户栈, 从CTE返回时, 内核线程的执行将会产生灾难性的后果.
对于这些受上下文切换影响的变量, 我们不能简单地将它们定义成全局变量. 它们本身是用于描述上下文的属性, 应该跟随着上下文一同进行切换, 因此在Context结构体中定义它们才是正确的做法:
void __am_asm_trap() {
if (pp == USER) { // pp is global
c->usp = $sp; // usp should be in Context
$sp = ksp; // ksp is global
}
c->np = pp; // np should be in Context
// save context
__am_irq_handle(c);
// restore context
pp = c->np;
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
CTE重入
除了上下文切换之外, 我们还需要考虑CTE的重入(re-entry)问题:
代码是否可能在离开CTE之前又再次进入CTE?
我们知道yield()是通过CTE来实现的, 如果用户进程通过系统调用陷入内核之后,
又执行了yield(), 就会出现CTE重入的现象.
另一种引发CTE重入的现象是上文介绍的中断嵌套:
第一次中断到来的时候代码会进入CTE, 但在第二次中断可能会在代码离开CTE之前到来.
不过在PA中不会出现中断嵌套的情况, 因为我们让处理器在进入CTE之后处于关中断状态.
CTE的重入会对上述代码产生什么影响呢? 借助程序的状态机视角来分析代码的行为, 我们很容易就知道问题了.
系统的复杂性(3)
我们把CTE重入问题作为状态机视角的一个练习, 请你来尝试分析上述代码在CTE重入的情况下存在什么问题.
为了解决这个问题, 我们需要对上述代码进行如下修改:
void __am_asm_trap() {
if (pp == USER) { // pp is global
c->usp = $sp; // usp should be in Context
$sp = ksp; // ksp is global
}
c->np = pp; // np should be in Context
pp = KERNEL; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
pp = c->np;
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
操作系统和中断
在真实的操作系统中, 系统调用的处理是在打开中断的状态下进行的.
这是因为系统调用的处理时间可能会非常长, 例如SYS_read可能会从机械磁盘中读取大量数据,
如果操作系统一直处于关中断的状态, 就无法及时响应系统中的各种中断请求:
通过时钟中断维护的系统时钟可能会产生明显的滞后,
网卡因为缓冲区满了而丢弃大量的网络包...
这就给操作系统的设计带来了很大的挑战: 因为中断的到来是不可预测的, 这就意味着CTE的重入可能会发生在系统调用处理过程中的任何地方. 更麻烦的是, 不止CTE的代码会产生重入, 操作系统中的很多代码也可能会产生重入. 因此操作系统开发者必须非常谨慎地编写相应的代码, 稍有不慎就会出现全局变量因重入而被覆盖的问题.
正因为这样的挑战, 我们在PA中就简单地通过关中断来回避这个问题. 事实上, 重入可以认为是一种特殊的并发, 在下学期的操作系统课上, 你将会对并发有更深刻的认识.
一些优化
我们可以对上述代码进行一些简单的优化.
一处可以优化的地方是把pp的功能合并到ksp中,
让ksp既可以表示内核栈的地址, 也可以表示进入CTE之前的特权级.
注意到ksp总是在pp == USER的时候被使用, 而且ksp的值肯定不为0,
因此我们可以通过ksp == 0来表示pp == KERNEL.
我们对ksp的值进行如下的约定:
- 若当前位于用户态, 则
ksp的值为内核栈的栈底 - 若当前位于内核态, 则
ksp的值为0
这样以后, 上述代码可以优化为:
void __am_asm_trap() {
if (ksp != 0) { // ksp is global
c->usp = $sp; // usp should be in Context
$sp = ksp;
}
c->np = (ksp == 0 ? KERNEL : USER); // np should be in Context
ksp = 0; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
另一处可以优化的地方是把c->usp的功能合并到c->sp中,
让c->sp表示进入CTE前$sp的值, 无论进入CTE前系统是位于用户态还是内核态.
同样地, 恢复上下文的时候, 直接把c->sp赋值给$sp即可.
这样就无需在Context结构体中额外定义usp了, 因此上述代码可以优化为:
void __am_asm_trap() {
c->sp = $sp;
if (ksp != 0) { // ksp is global
$sp = ksp;
}
c->np = (ksp == 0 ? KERNEL : USER); // np should be in Context
ksp = 0; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
if (c->np == USER) {
ksp = $sp;
}
$sp = c->sp;
return_from_trap();
}
栈切换的具体实现
上文讨论的只是概念上的解决方案, 为了在代码中实现内核栈的切换, 我们还需要把上文中提到的几个概念变量映射到ISA相关的具体实现中.
mips32
对内核栈切换的实现来说, mips32是最简单的.
根据mips32 ABI的约定, 通用寄存器中预留了k0和k1两个寄存器专门给内核使用,
编译器不会把变量分配到k0或k1中.
因此我们可以进行如下约定:
- 把概念上的
ksp映射到k0寄存器 - 把概念上的
c->np映射到c->gpr[k1] - 把概念上的
c->sp映射到c->gpr[sp]
你只需要根据上述约定在CTE中添加少量代码, 就可以实现内核栈切换的功能了.
riscv32
和mips32不同, riscv32 ABI并没有约定类似k0和k1的寄存器用法.
相反地, riscv32提供了一个叫mscratch的CSR寄存器, 专门作为临时寄存器给系统软件使用,
它在硬件的行为上并没有什么特殊之处.
因此我们可以进行如下约定:
- 把概念上的
ksp映射到mscratch寄存器 - 在Context结构体中添加一个新的成员
np, 把概念上的c->np映射到它 - 把概念上的
c->sp映射到c->gpr[sp]
不过当你打算实现代码的时候, 你会发现在刚进入CTE而未切换到内核栈之前, 我们根本没有空闲的通用寄存器可以使用! 事实上, riscv32的设计非常精巧, 我们可以通过3条指令来完成内核栈的切换:
__am_asm_trap:
csrrw sp, mscratch, sp // (1) atomically exchange sp and mscratch
bnez sp, save_context // (2) take the branch if we trapped from user
csrr sp, mscratch // (3) if we trapped from kernel, restore the original sp
save_context:
// now sp is pointing to the kernel stack
// save the context...
为了检查mscratch的值, 我们通过(1)巧妙地使用了CSR访问指令的原子交换功能来交换sp和mscratch的值,
这样既可以把原来的mscratch值读到通用寄存器sp中进行比较(riscv32的分支指令不能访问CSR寄存器),
又可以把原来的sp值保存到mscratch寄存器中避免被破坏.
接下来通过(2)判断刚才读出的mscratch值(即概念上的ksp):
如果值是0, 说明在进入CTE之前是内核态,
而此时内核栈的指针已经被(1)交换到mscratch寄存器中了, 于是通过(3)把内核栈的指针读回来;
如果值不是0, 说明在进入CTE之前是用户态, 需要把sp切换到内核栈,
但指令(1)已经完成了这一切换工作了, 因此此时直接跳转到save_context处来保存上下文即可.
临时寄存器的方案
同样是作为CTE的临时寄存器, mips32选择在GPR中分配出k0和k1,
而riscv32则是采用mscratch这个CSR寄存器.
这两种方案相比, 是否存在哪一种方案更优? 为什么?
x86
在x86中实现内核栈的切换则比较特殊, 这是因为x86的异常处理机制会直接把
eflags, cs和eip保存到栈上, 软件代码无法干涉这一行为.
如果我们希望把这3个寄存器保存到内核栈上, 那就需要由x86硬件来进行内核栈的切换.
类似地, x86的iret指令通过弹栈的方式恢复现场的.
这意味着我们同样无法通过软件来恢复用户栈的栈指针:
如果我们在iret指令之前先切换到用户栈, 那么iret指令就无法找到正确的eflags, cs和eip;
但如果我们先执行iret指令, eip将会指向用户代码, 此时我们已经无法恢复用户栈的栈指针.
因此x86必须通过硬件机制来提供上述问题的解决方案. 首先我们必须让硬件识别出当前的特权级,
这是通过CS寄存器中的RPL域来识别的(也即i386手册中CPL的定义),
若CS.RPL为0, 表示处理器处于内核态; 若CS.RPL为3, 表示处理器处于用户态.
然后我们根据根据i386手册对x86的异常处理机制和iret指令的行为进行扩展:
- 若异常发生在内核态, 则异常处理机制的行为与PA3的介绍一致
(见i386手册中Figure 9-5的
WITHOUT PRIVILEGE TRANSITION) - 若异常发生在用户态, 则异常处理机制先通过TSS机制找到
ksp, 然后往ksp中先压入ss(栈段寄存器)和esp, 最后再压入eflags,cs和eip(见i386手册中Figure 9-5的WITH PRIVILEGE TRANSITION) - 执行
iret指令时, 先依次弹出eip,cs和eflags, 若此时弹出的cs表示将要返回到用户态, 则再继续弹出esp和ss
完整的TSS机制有两个作用, 一是用于在硬件上进行上下文切换, 二是用于在用户态发生异常时进行内核栈的切换, 在PA中我们只需要关心后者即可. 但要介绍TSS机制, 我们就不得不引入我们本来希望在PA中简化掉的分段机制了. 不过你在PA3已经对异常处理机制有所了解了, 这会对你理解TSS机制有所帮助. 我们先来回顾一下x86的异常处理机制:
从IDTR寄存器中读出IDT这个数组的首地址, 用异常号对IDT进行索引, 得到一个门描述符, 然后把门描述符中的offset域组合成一个地址.
然后我们就可以来类比TSS机制的处理过程了:
从GDTR寄存器中读出GDT这个数组的首地址, 用TR寄存器中的idx域对GDT进行索引, 得到一个TSS描述符, 然后把TSS描述符中的base域组合成一个地址.
噢, 好像也不是特别难理解.
不过异常处理机制中最终得到的地址是异常入口地址, 而TSS机制最终得到的地址则是TSS结构体的地址.
TSS结构体中有非常多的成员, 但在内核栈的切换过程中, 硬件只会用到ss0和esp0这两个成员
(见abstract-machine/am/src/x86/x86.h中TSS32结构体的定义).
ICS课本的第七章介绍了带TSS机制的异常处理过程, 关于TSS机制的细节, 也可以查阅i386手册.
由于硬件TSS机制的支持, CTE在软件上只需要维护概念变量ksp就可以了:
- 把概念上的
ksp映射到TSS结构体中的esp0成员 - 把概念上的
c->np映射到c->cs.RPL - 在Context结构体中添加两个新的成员
ss3和esp3, 把概念上的c->sp(实际上是c->usp)映射到c->esp3
为了让TSS机制在将来可以正确工作, 我们还需要在cte_init()中添加一些初始化代码:
#define NR_SEG 6
static SegDesc gdt[NR_SEG] = {};
static TSS32 tss = {};
bool cte_init(Context*(*handler)(Event, Context*)) {
// ...
// initialize GDT
gdt[1] = SEG32(STA_X | STA_R, 0, 0xffffffff, DPL_KERN);
gdt[2] = SEG32(STA_W, 0, 0xffffffff, DPL_KERN);
gdt[3] = SEG32(STA_X | STA_R, 0, 0xffffffff, DPL_USER);
gdt[4] = SEG32(STA_W, 0, 0xffffffff, DPL_USER);
gdt[5] = SEG16(STS_T32A, &tss, sizeof(tss) - 1, DPL_KERN);
set_gdt(gdt, sizeof(gdt[0]) * NR_SEG);
// initialize TSS
tss.ss0 = KSEL(2);
set_tr(KSEL(5));
return true;
}
我们在GDT这个数组中设置了5个描述符, 前4个分别表示内核态代码段, 内核态数据段, 用户态代码段, 用户态数据段, 它们是为了在DiffTest的时候可以让QEMU正确地进行特权级的处理, 我们无需关心其中的细节.
实现内核栈和用户栈之间的切换
理解上述讲义内容, 修改CTE的代码, 使其支持内核栈和用户栈之间的切换.
你需要了解你的实现中是如何体现上述伪代码的功能, 同时, 根据不同概念变量的性质,
你可能还需要在cte_init()或者kcontext()/ucontext()中对它们进行初始化.
如果你希望在__am_irq_handle()中维护这些概念变量, 必要的时候可以采用内联汇编.
实现后, 让Nanos-lite加载NTerm和hello这两个用户进程, 然后从NTerm启动仙剑奇侠传. 如果你的实现正确, 你将可以看到hello用户进程和NTerm/仙剑奇侠传分时运行. 和之前的效果不同, 这次我们真正实现了两个用户进程的分时运行.
一些提示:
- 为了方便调试, 你可以先在NEMU中关闭时钟中断, 这样可以提升系统的确定性, 测试成功后再打开时钟中断
- mips32 - 在保存上下文之前,
k1就已经是一个可用的寄存器 - riscv32 - 为了维护
c->np, 你可能需要在切换到内核栈之后马上保存少部分GPR, 或者借助全局变量来帮助你 - x86 - 除了在硬件上实现必要的寄存器和硬件机制, 你还需要进行以下的初始化:
- 在
kcontext()中把c->cs设置成KSEL(1) - 在
ucontext()中把c->cs设置成USEL(3), 把c->ss3设置成USEL(4)
- 在
需要注意的是, 我们目前只允许最多一个需要更新画面的进程参与调度, 这是因为多个这样的进程并发运行会导致画面被相互覆盖, 影响画面输出的效果. 在真正的图形界面操作系统中, 通常由一个窗口管理进程来统一管理画面的显示, 需要显示画面的进程与这一管理进程进行通信, 来实现更新画面的目的. 但这需要操作系统支持进程间通信的机制, 这已经超出了ICS的范围, 而且Nanos-lite作为一个裁剪版的操作系统, 也不提供进程间通信的服务. 因此我们进行了简化, 最多只允许一个需要更新画面的进程参与调度即可.
真实系统的复杂性
通过剖析"并发执行多个用户进程"需要解决的问题和方案, 我们看了到当一些学过的知识点组合起来的时候, 问题的复杂度可能会指数增长: 中断随时会到来, 自陷操作可能会发生, 这些都可能会引发上下文切换; 一方面这可能会导致虚拟地址空间的切换, 另一方面在上下文返回的时候, 有可能需要切换到用户栈, 也有可能切换到内核栈, 而这又取决于一些变量的维护; 这些变量虽然都是用过C语言来定义和使用, 但在中断异常和上下文切换的共同作用下, 全局变量以及Context结构体中的成员变量有着不同的生存期, 我们需要根据不同的场景将一些关键的变量定义到不同的位置...
现代计算机系统一般都配备多核处理器, 运行着多核操作系统, 于是多了一类和处理器数量相关的变量; 除了中断异常的处理带来并发的场景之外, 多个处理器甚至会真正地并行执行代码, 如何在多核系统中正确地解决各种并发问题 一直以来都是计算机系统领域的一个挑战.
Nanos-lite与并发bug (建议二周目/学完操作系统课思考)
上文讨论并发的时候提到: 更一般地, 用户进程都会并发地执行系统调用, 操作系统还需要保证它们都能按照系统调用的语义正确地执行.
我们在PA3中知道printf()会通过malloc()申请缓冲区,
而malloc()又可能会执行_sbrk(), 通过SYS_brk陷入内核;
在上一个阶段中, 我们实现了支持分页机制的mm_brk(),
在必要的时候它会通过new_page()申请一页.
而仙剑和hello用户进程都会调用printf(), 使得它们可能会并发执行SYS_brk.
思考一下, 目前Nanos-lite的设计会导致并发bug吗? 为什么?