实验十 CPU数据通路
我梦见自己慢慢地升了起来,穿过数据平面,穿过数据网,进入并穿过万方网,最后来到了一个不认识的地方,我从没梦见过的地方……这个地方,空间无限,颜色悠闲、难以形容,没有地平线,没有天,没有地或者人类称为地面的实体区。
— 《海伯利安的陨落》, 丹·西蒙斯
本实验的目标是利在单周期CPU的实现之前,先完成CPU数据通路中的三个重要部分:寄存器堆、ALU和数据存储器,并通过功能仿真测试。
寄存器堆
寄存器堆是CPU中用于存放指令执行过程中临时数据的存储单元。 我们将要实现的RISC-V的基础版本CPU RV32I具有32个寄存器。 RV32I采用 Load Store 架构,即所有数据都需要先用Load语句从内存中读取到寄存器里才可以进行算术和逻辑操作。 因此,RV32I有32个通用寄存器,且每条算术运算可能要同时读取两个源寄存器并写入一个目标寄存器。 为支持高速,多端口并行存取的寄存器堆,我们不能直接调用通用的RAM,而需要用Verilog语言单独编写寄存器堆。
RV32I中的通用寄存器
RV32I共32个32bit的通用寄存器x0~x31(寄存器地址为5bit编码),其中寄存器x0中的内容总是0,无法改变。
其他寄存器的别名和寄存器使用约定参见表 Table 12 。需要注意的是,部分寄存器在函数调用时是由调用方(Caller)来负责保存的,部分寄存器是由被调用方(Callee)来保存的。在进行C语言和汇编混合编程时需要注意。
Register |
Name |
Use |
Saver |
|---|---|---|---|
x0 |
zero |
Constant 0 |
– |
x1 |
ra |
Return Address |
Caller |
x2 |
sp |
Stack Pointer |
Callee |
x3 |
gp |
Global Pointer |
– |
x4 |
tp |
Thread Pointer |
– |
x5~x7 |
t0~t2 |
Temp |
Caller |
x8 |
s0/fp |
Saved/Frame pointer |
Callee |
x9 |
s1 |
Saved |
Callee |
x10~x11 |
a0~a1 |
Arguments/Return Value |
Caller |
x12~x17 |
a2~a7 |
Arguments |
Caller |
x18~x27 |
s2~s11 |
Saved |
Callee |
x28~x31 |
t3~t6 |
Temp |
Caller |
寄存器堆实现
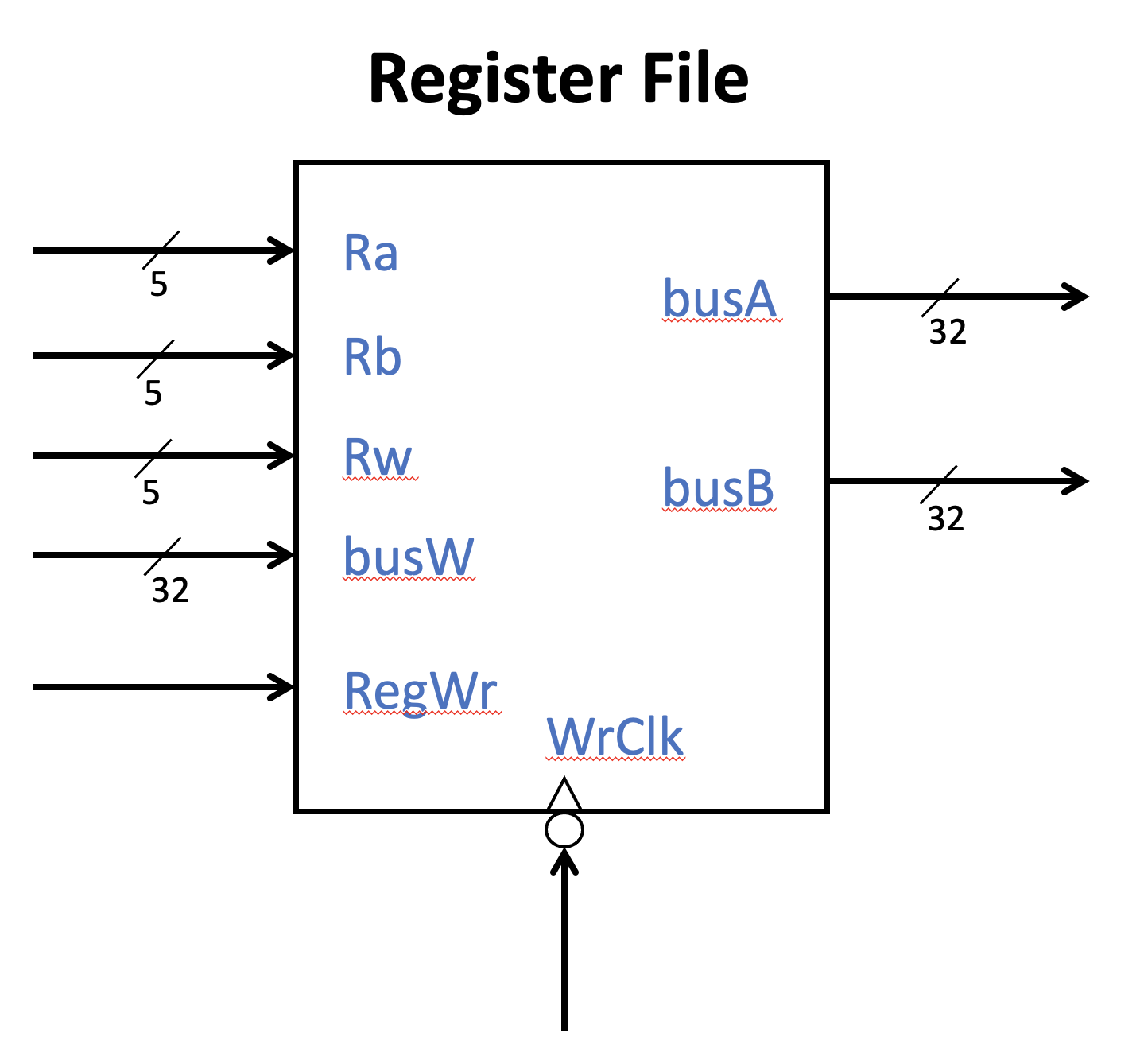
Fig. 70 寄存器堆接口示意图
图 Fig. 70 描述了寄存器堆的接口,该寄存器堆中有32个32bit的寄存器。 寄存器堆需要支持同时两个读操作和一个写操作。因此需要有2个读地址Ra和Rb,分别对应RISC-V汇编中的rs1和rs2。写地址为Rw,对应rd。地址均是5位。 写入数据busW为32位,写入有效控制为一位高电平有效的RegWr信号。 寄存器堆的输出是2个32位的寄存器数据,分别是busA和busB。 寄存器堆有一个控制写入的时钟WrClk。 在时序上我们可以让读取是非同步的,即地址改变立刻输出。写入可以在时钟下降沿写入。 注意,寄存器x0需要特殊处理,不论何时都是全零。请自行思考如何实现x0寄存器。
ALU
ALU是CPU中的核心数据通路部件之一,它主要完成CPU中需要进行的算术逻辑运算, 我们在前面的实验中已经实现了一个简单的ALU。在本实验中只需要对该ALU稍加改造即可。 针对RV32I的运算需求,我们对ALU的控制信号进行了重新定义,如表 Table 10 所示。 该ALU的逻辑图如图 Fig. 71 所示。 ALU对输入数据并行地进行加减法、移位、比较大小、异或等操作。 最终ALUout输出是通过一个八选一选择器选择不同运算部件的结果,选择器的控制端可以用ALUctr[2:0]直接生成。 ALU中其他部件的控制信号包括:A/L控制移位器进行算术移位还是逻辑移位,L/R控制是左移还是右移,U/S控制比较大小是带符号比较还是无符号比较,S/A控制是加法还是减法。 这些控制信号需要按照所需进行的操作对应设置,请同学们自行设计。注意:比较大小或判断相等时应使用减法操作。
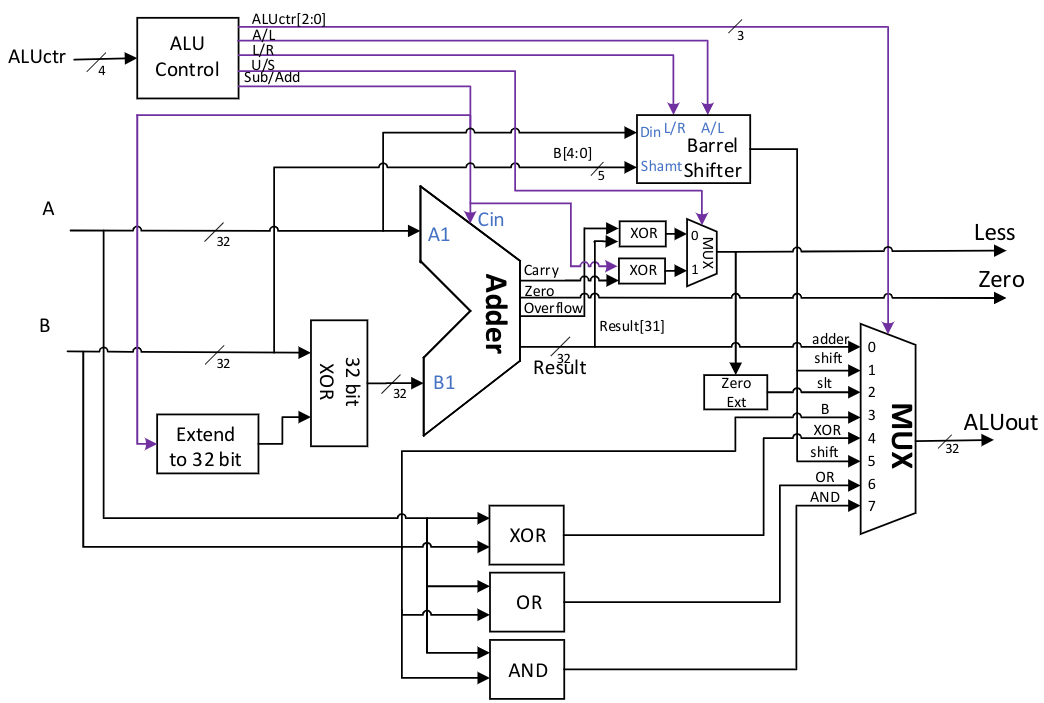
Fig. 71 ALU电路示意图
ALUctr[3] |
ALUctr[2:0]} |
ALU操作 |
|---|---|---|
0 |
000 |
选择加法器输出,做加法 |
1 |
000 |
选择加法器输出,做减法 |
\(\times\) |
001 |
选择移位器输出,左移 |
0 |
010 |
做减法,选择带符号小于置位结果输出, Less按带符号结果设置 |
1 |
010 |
做减法,选择无符号小于置位结果输出, Less按无符号结果设置 |
\(\times\) |
011 |
选择ALU输入B的结果直接输出 |
\(\times\) |
100 |
选择异或输出 |
0 |
101 |
选择移位器输出,逻辑右移 |
1 |
101 |
选择移位器输出,算术右移 |
\(\times\) |
110 |
选择逻辑或输出 |
\(\times\) |
111 |
选择逻辑与输出 |
数据存储器
数据存储器在CPU运行中存储全局变量、堆栈等数据。我们建议大家实现至少128kB大小的数据存储器容量。 并且,该数据存储器需要支持在沿上进行读取和写入操作。RV32I的字长是32bit,但是,数据存储器不仅要支持32bit数据的存取,同时也需要支持按字节(8bit)或半字(16bit)大小的读取。 由于单周期CPU需要在一个周期内完成一条指令的所有操作,我们需要数据RAM有独立的读时钟和写时钟。其中读取操作在系统时钟的上升沿进行(即一个时钟周期的一半时刻),写操作在系统时钟的下降沿进行(即一个时钟周期的结束时刻)。建议使用双端口RAM(RAM 2 PORT)来实现数据存储器。DE10-Standard开发板上的大容量SRAM是支持独立的读写时钟的。一般可以支持128KB以上的数据存储容量。
要实现按字节(8 bit)或按半字(16 bit)大小的读写,需要同学们对IP核生成的存储器进行一定程度的改造。 在实现过程中不需要考虑4字节读写或2字节读写时地址未对齐的情况。默认4字节读写时地址低2位为00,2字节读写时地址最低位为0。
具体地,MemOP信号定义如下: 宽度为3bit,控制数据存储器读写格式,为 010 时为4字节读写,为001 时为2字节读写带符号扩展,为000时为1字节读写带符号扩展为 101时为2 字节读写无符号扩展为100时为1字节读写无符号扩展。
MemOP与RV32中的存储器操作对应关系如下:
指令 |
MemOP |
操作 |
|---|---|---|
lb rd,imm12(rs1)} |
000 |
\(R[rd] \leftarrow SEXT(M_{1B}[ R[rs1] + SEXT(imm12) ])\) |
lh rd,imm12(rs1)} |
001 |
\(R[rd] \leftarrow SEXT(M_{2B}[ R[rs1] + SEXT(imm12) ])\) |
lw rd,imm12(rs1)} |
010 |
\(R[rd] \leftarrow M_{4B}[ R[rs1] + SEXT(imm12) ]\) |
lbu rd,imm12(rs1)} |
100 |
\(R[rd] \leftarrow \{24'b0, M_{1B}[ R[rs1] + SEXT(imm12) ]\) |
lhu rd,imm12(rs1)} |
101 |
\(R[rd] \leftarrow \{16'b0, M_{2B}[ R[rs1] + SEXT(imm12) ]\) |
sb rs2,imm12(rs1)} |
000 |
\(M_{1B}[ R[rs1] + SEXT(imm12) ] \leftarrow R[rs2][7:0]\) |
sh rs2,imm12(rs1)} |
001 |
\(M_{2B}[ R[rs1] + SEXT(imm12) ] \leftarrow R[rs2][15:0]\) |
sw rs2,imm12(rs1)} |
010 |
\(M_{4B}[ R[rs1] + SEXT(imm12) ] \leftarrow R[rs2]\) |
对于读取操作,我们可以每次均读取32bit的数据,然后根据MemOP来判断是需要8bit,16bit还是32bit的数据,再根据地址的低2位选择合适的数据拼接扩展成读取的结果即可。
对于写入操作,由于需要对32bit中特定的8bit或16bit数据进行写入,而不能破坏其他比特。因此在实现上需要慎重思考。我们提供以下三种解决思路,供大家参考。
利用IP核中支持单字节写入使能信号的双口RAM来实现。
这种方式是我们推荐的方式。如图 Fig. 72 所示,在Quartus中配置双端口RAM的第3步时,我们可以选择生成单字节写入使能信号。例如,我们生成了位宽为32bit的RAM后,系统会对应生成byteena_a[3:0]的单字节写入使能信号,该信号是高有效。如果需要对32位四个Byte同时写入,可以将这个信号置为4’b1111。如果只需要写入低8位,可以将这个信号置为4’b0001。所以,在进行字节或半字写入时,我们只需要对应设置单字节写使能信号,并将写入的数据按正确的方式组成32bit一次性写入即可。
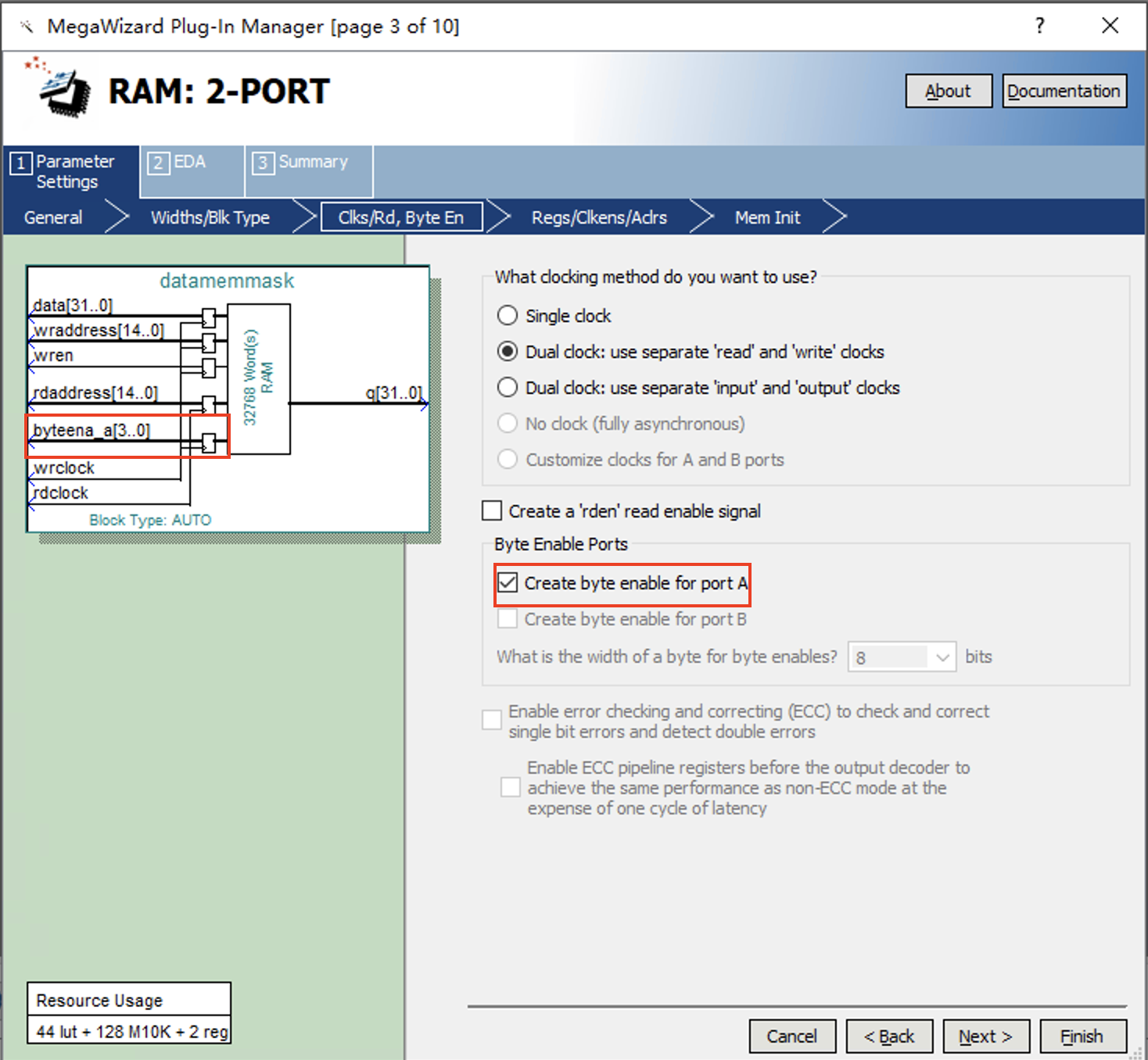
Fig. 72 双端口RAM中的单字节写入使能配置
在写入之前先读取原有数据,修改后一次性写入32比特。
IP核生成的RAM不支持在仿真过程中对数据进行多次初始化,我们也可以用自己改写的RAM替代上述IP核中的带单字节写使能的RAM用于仿真。 我们观察到,在单周期CPU中,CPU在一个周期内只可能对内存执行读操作或写操作中的一种。因此,如果我们要写入8bit的数据又不想改变与它相邻的其他比特,我们可以在时钟上升沿读取将要写入的单元而不是读地址对应的单元。对读取的数据进行修改后,在下降沿将数据再次写回去即可。 注意,此时要求写使能信号和写地址要在时钟上升沿就准备好。我们提供了如下的实现示例,其接口和IP核生成的双端口RAM是一致的。
module testdmem(
byteena_a,
data,
rdaddress,
rdclock,
wraddress,
wrclock,
wren,
q);
input [3:0] byteena_a;
input [31:0] data;
input [14:0] rdaddress;
input rdclock;
input [14:0] wraddress;
input wrclock;
input wren;
output reg [31:0] q;
reg [31:0] tempout;
wire [31:0] tempin;
reg [31:0] ram [32767:0];
always@(posedge rdclock)
begin
if(wren)
tempout<=ram[wraddress];
else
q <= ram[rdaddress];
end
assign tempin[7:0] = (byteena_a[0])? data[7:0] : tempout[7:0];
assign tempin[15:8] = (byteena_a[1])? data[15:8] : tempout[15:8];
assign tempin[23:16] = (byteena_a[2])? data[23:16]: tempout[23:16];
assign tempin[31:24] = (byteena_a[3])? data[31:24]: tempout[31:24];
always@(posedge wrclock)
begin
if(wren)
begin
ram[wraddress]<=tempin;
end
end
endmodule
非标准的RAM模块
这类自己写的RAM模块Quartus很有可能不会将其映射到M10K内存模块上来实现,直接导致系统资源不够或编译时间较长。在实际上板的代码中建议对于容量大于64k的存储都采用IP核生成的RAM。
利用4片8bit RAM拼接成一个32bit的存储器。
这种方法用4片8bit的RAM拼接成一个32bit的RAM,每个8bitRAM负责32比特的给定部分。例如,RAM0负责提供地址低两位为00的数据,RAM1负责提供地址低两位为01的数据,以此类推。 如果需要一次性读写32bit数据,我们将对应的数据和地址前30位连接到4片RAM上即可同时对4片RAM进行操作,一次读写 \(4\times8=32\) bit数据。 如果只需要写入8bit数据,可以根据地址低两位来控制RAM写使能端口,只对一片RAM进行写入。 这种方法主要的问题是内存初始化的时候需要对四片RAM分别进行初始化,有一些麻烦。
实验验收要求
在线测试
请单独完成CPU的寄存器堆、ALU和数据存储器的实现,并能够顺利通过两个在线测试。