实验十一 RV32I单周期CPU
“陛下,我们把这台计算机命名为‘秦一号’。请看,那里,中心部分,是CPU,是计算机的核心计算元件。由您最精锐的五个军团构成,对照这张图您可以看到里面的加法器、寄存器、堆栈存贮器;外围整齐的部分是内存,构建这部分时我们发现人手不够,好在这部分每个单元的动作最简单,就训练每个士兵拿多种颜色的旗帜,组合起来后,一个人就能同时完成最初二十个人的操作,这就使内存容量达到了运行‘秦1.0’操作系统的最低要求;”
— 《三体》, 刘慈欣
本实验的目标是利用FPGA实现RV32I指令集中除系统控制指令之外的其余指令。利用单周期方式实现RV32I的控制通路及数据通路,并能够顺利通过功能仿真。在完成功能仿真后可以在DE10-Standard开发板上进行单步测试。通过对单周期CPU的实际设计来理解CPU内部的控制及数据通路原理,并掌握基本的系统级测试和Debug技术。
RISC-V指令集简介
RISC-V 是由UC Berkeley推出的一套开源指令集。 该指令集包含一系列的基础指令集和可选扩展指令集。在本实验中我们主要关注其中的32位基础指令集RV32I。 RV32I指令集中包含了40条基础指令,涵盖了整数运算、存储器访问、控制转移和系统控制几个大类。本实验中无需实现系统控制的ECALL/EBREAK、内存同步FENCE指令及CSR访问指令,所以共需实现37条指令。 RV32I中的程序计数器PC及32个通用寄存器均是32位长度,访存地址线宽度也是32位。RV32I的指令长度也统一为32位,在实现过程中无需支持16位的压缩指令格式。
RV32I指令编码
RV32I的指令编码非常规整,分为六种类型,其中四种类型为基础编码类型,其余两种是变种:
R-Type :为寄存器操作数指令,含2个源寄存器rs1,rs2和一个目的寄存器rd。
I-Type :为立即数操作指令,含一个源寄存器和一个目的寄存器和一个12bit立即数操作数
S-Type :为存储器写指令,含两个源寄存器和一个12bit立即数。
B-Type:为跳转指令,实际是S-Type的变种。与S-Type主要的区别是立即数编码。S-Type中的imm[11:5]变为{immm[12], imm[10:5]},imm[4:0]变为{imm[4:1], imm[11]}。
U-Type :为长立即数指令,含一个目的寄存器和20bit立即数操作数。
J-Type:为长跳转指令,实际是U-Type的变种。与U-Type主要的区别是立即数编码。U-Type中的imm[31:12]变为{imm[20], imm[10:1], imm[11], imm[19:12]}。
其中四种基本格式如图 Fig. 73 所示:
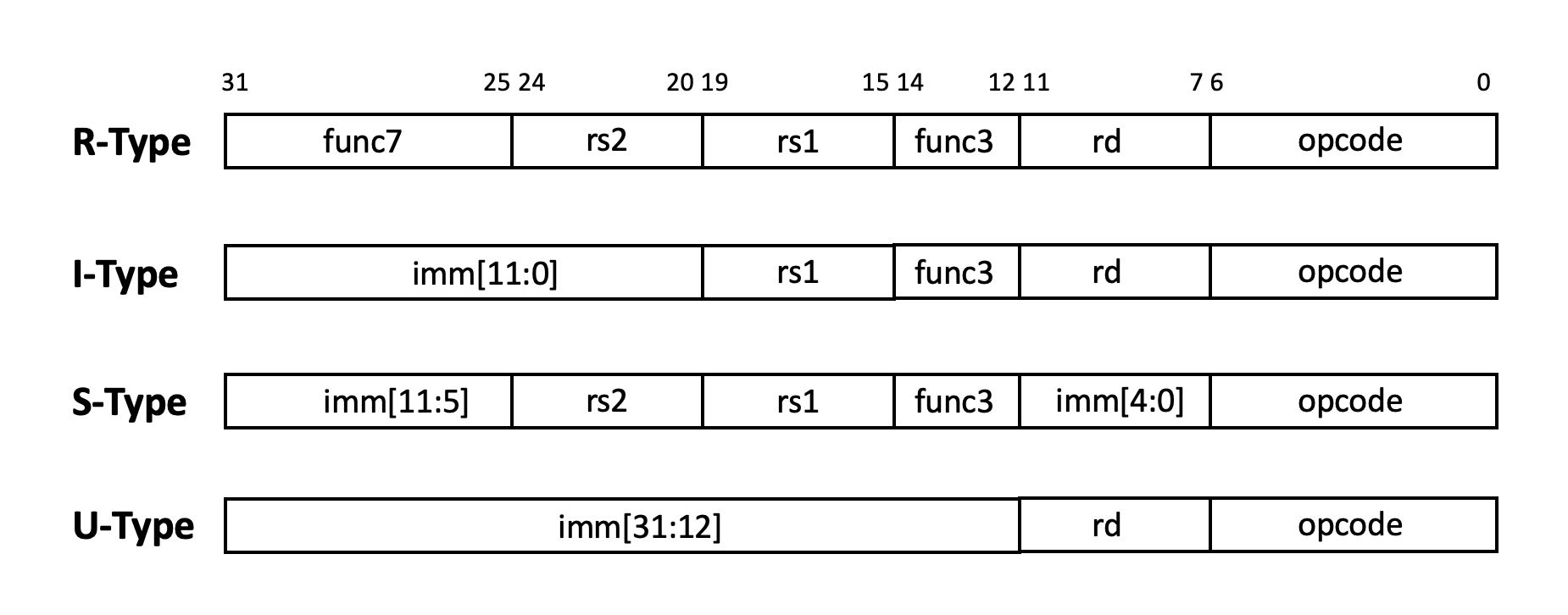
Fig. 73 RV32I指令的四种基本格式
在指令编码中,opcode必定为指令低7bit,源寄存器rs1,rs2和目的寄存器rd也都在特定位置出现,所以指令解码非常方便。
思考
为什么会有S-Type/B-Type,U-Type/J-Type这些不同的立即数编码方案?指令相关的立即数为何在编码时采用这样“奇怪”的bit顺序?
RV32I中的通用寄存器
RV32I共32个32bit的通用寄存器x0~x31(寄存器地址为5bit编码),其中寄存器x0中的内容总是0,无法改变。 其他寄存器的别名和寄存器使用约定参见表 Table 12 。需要注意的是,部分寄存器在函数调用时是由调用方(Caller)来负责保存的,部分寄存器是由被调用方(Callee)来保存的。在进行C语言和汇编混合编程时需要注意。
Register |
Name |
Use |
Saver |
|---|---|---|---|
x0 |
zero |
Constant 0 |
– |
x1 |
ra |
Return Address |
Caller |
x2 |
sp |
Stack Pointer |
Callee |
x3 |
gp |
Global Pointer |
– |
x4 |
tp |
Thread Pointer |
– |
x5~x7 |
t0~t2 |
Temp |
Caller |
x8 |
s0/fp |
Saved/Frame pointer |
Callee |
x9 |
s1 |
Saved |
Callee |
x10~x11 |
a0~a1 |
Arguments/Return Value |
Caller |
x12~x17 |
a2~a7 |
Arguments |
Caller |
x18~x27 |
s2~s11 |
Saved |
Callee |
x28~x31 |
t3~t6 |
Temp |
Caller |
RV32I中的指令类型
本实验中需要实现的RV32I指令含包含以下三类:
整数运算指令 :可以是对两个源寄存器操作数,或一个寄存器一个立即数操作数进行计算后,结果送入目的寄存器。运算操作包括带符号数和无符号数的算术运算、移位、逻辑操作和比较后置位等。
控制转移指令 :条件分支包括beq,bne等等,根据寄存器内容选择是否跳转。无条件跳转指令会将本指令下一条指令地址PC+4存入rd中供函数返回时使用。
存储器访问指令 :对内存操作是首先寄存器加立即数偏移量,以计算结果为地址读取/写入内存。读写时可以是按32位字,16位半字或8位字节来进行读写。读写时区分无符号数和带符号数。注意:RV32I为 Load/Store 型架构,内存中所有数据都需要先load进入寄存器才能进行操作,不能像x86一样直接对内存数据进行算术处理。
整数运算指令
RV32I的整数运算指令包括21条不同的指令,其指令编码方式参见表 Fig. 74 。
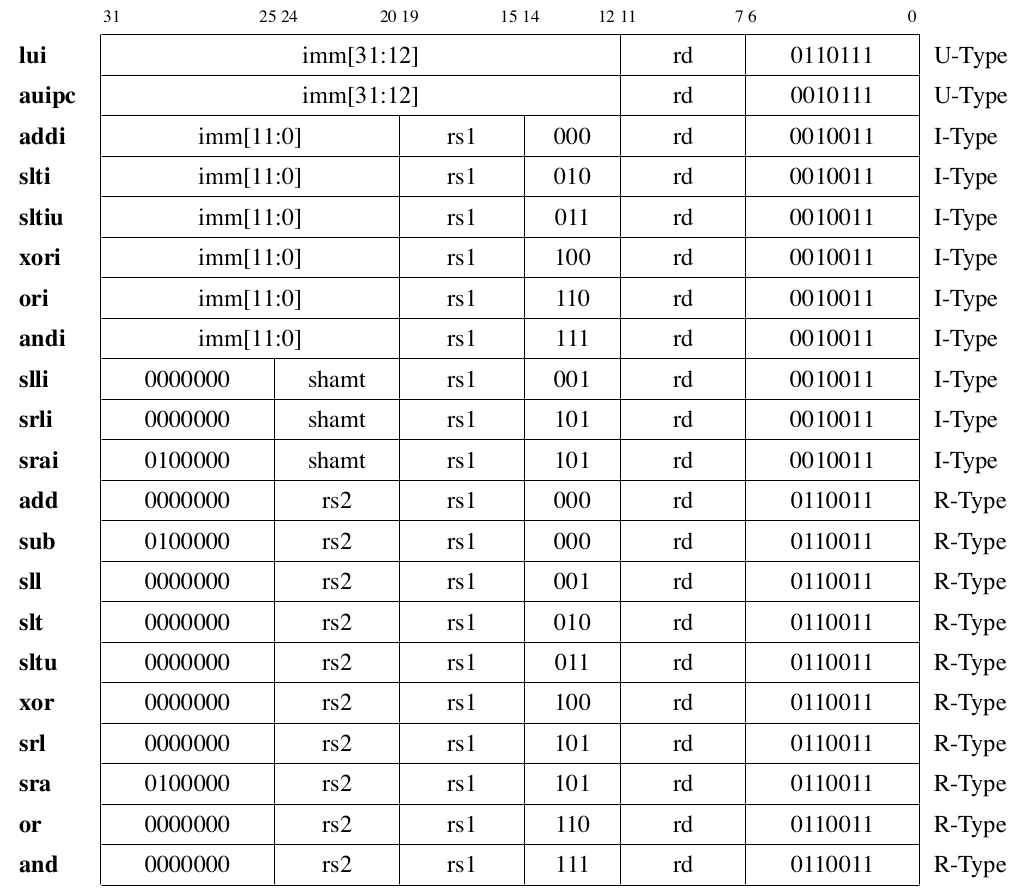
Fig. 74 RV32I中整数运算指令编码列表
这些整数运算指令所需要完成的操作参见表 Table 13 。说明中R[reg]表示对地址为reg的寄存器进行操作,M[addr]表示对地址为addr的内存进行操作,SEXT(imm)表示对imm进行带符号扩展到32位, \(\leftarrow\) 表示赋值, << 及 >> 分别表示逻辑左移和右移, >>> 表示算术右移(注意verilog与java中定义的不同),比较过程中带s和u下标分别表示带符号数和无符号数比较。
指令 |
操作 |
|---|---|
lui rd,imm20 |
\(R[rd] \leftarrow \{imm20, 12'b0\}\) |
auipc rd,imm20 |
\(R[rd] \leftarrow PC + \{imm20, 12'b0\}\) |
addi rd,rs1,imm12 |
\(R[rd] \leftarrow R[rs1] + SEXT(imm12)\) |
slti rd,rs1,imm12 |
\(if\ R[rs1] <_s SEXT(imm12)\ then\ R[rd] \leftarrow 32'b1 else R[rd] \leftarrow 32'b0\) |
sltiu rd,rs1,imm12 |
\(if\ R[rs1] <_u SEXT(imm12)\ then\ R[rd] \leftarrow 32'b1 else R[rd] \leftarrow 32'b0\) |
xori rd,rs1,imm12 |
\(R[rd] \leftarrow R[rs1] \oplus SEXT(imm12)\) |
ori rd,rs1,imm12 |
\(R[rd] \leftarrow R[rs1] | SEXT(imm12)\) |
andi rd,rs1,imm12 |
\(R[rd] \leftarrow R[rs1] \& SEXT(imm12)\) |
slli rd,rs1,shamt |
\(R[rd] \leftarrow R[rs1] << shamt\) |
srli rd,rs1,shamt |
\(R[rd] \leftarrow R[rs1] >> shamt\) |
srai rd,rs1,shamt |
\(R[rd] \leftarrow R[rs1] >>> shamt\) |
add rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] + R[rs2]\) |
sub rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] - R[rs2]\) |
sll rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] << R[rs2][4:0]\) |
slt rd,rs1,rs2 |
\(if\ R[rs1] <_s R[rs2] \hspace{0.1in} then\ R[rd] \leftarrow 32'b1 else R[rd] \leftarrow 32'b0\) |
sltu rd,rs1,rs2 |
\(if\ R[rs1] <_u R[rs2] \hspace{0.1in} then\ R[rd] \leftarrow 32'b1 else R[rd] \leftarrow 32'b0\) |
xor rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] \oplus R[rs2]\) |
srl rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] >> R[rs2][4:0]\) |
sra rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] >>> R[rs2][4:0]\) |
or rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] | R[rs2]\) |
and rd,rs1,rs2 |
\(R[rd] \leftarrow R[rs1] \& R[rs2]\) |
细心的同学可能会注意到基本的整数运算指令并没有完全覆盖到所有的运算操作。RV32I中基本指令集可以通过伪指令或组合指令的方式来实现基本指令中未覆盖到的功能,具体可以参考 常见伪指令 节。对于乘除法这样的功能是通过软件实现的,在下一实验中会介绍。
控制转移指令
RV32I中包含了6条分支指令和2条无条件转移指令。图 Fig. 75 列出了这些控制转移指令的编码方式。
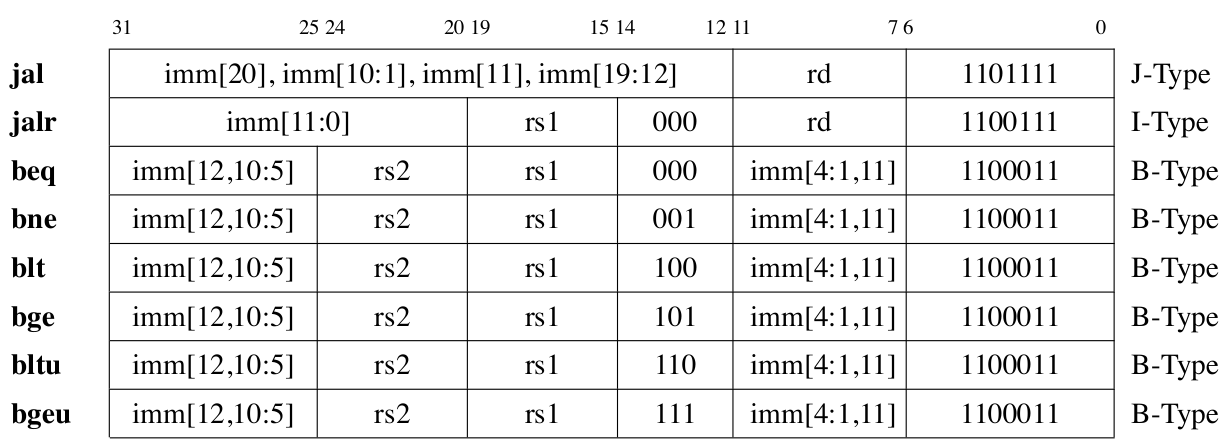
Fig. 75 RV32I 中控制转移指令编码列表
指令 |
操作 |
|---|---|
jal rd,imm20 |
\(makecell[l]{R[rd] \leftarrow PC + 4\\ PC \leftarrow (PC + SEXT(\{imm20,1'b0\}))}\) |
jalr rd,rs1,imm12 |
\(\makecell[l]{R[rd] \leftarrow PC + 4\\ PC \leftarrow (R[rs1] + SEXT(imm12)) \& 0xfffffffe}\) |
beq rs1,rs2,imm12 |
\(\emph{if} R[rs1]==R[rs2] \emph{then} PC \leftarrow PC + SEXT(\{imm12,1'b0\})) \emph{else} PC \leftarrow PC + 4\) |
bne rs1,rs2,imm12 |
\(\emph{if} R[rs1]!=R[rs2] \emph{then} PC \leftarrow PC + SEXT(\{imm12,1'b0\})) \emph{else} PC \leftarrow PC + 4\) |
blt rs1,rs2,imm12 |
\(\emph{if} R[rs1] <_s R[rs2] \emph{then} PC \leftarrow PC + SEXT(\{imm12,1'b0\})) \emph{else} PC \leftarrow PC + 4\) |
bge rs1,rs2,imm12 |
\(\emph{if} R[rs1] \ge_s R[rs2] \emph{then} PC \leftarrow PC + SEXT(\{imm12,1'b0\})) \emph{else} PC \leftarrow PC + 4\) |
bltu rs1,rs2,imm12 |
\(\emph{if} R[rs1] <_u R[rs2] \emph{then} PC \leftarrow PC + SEXT(\{imm12,1'b0\})) \emph{else} PC \leftarrow PC + 4\) |
bgeu rs1,rs2,imm12 |
\(\emph{if} R[rs1] \ge_u R[rs2] \emph{then} PC \leftarrow PC + SEXT(\{imm12,1'b0\})) \emph{else} PC \leftarrow PC + 4\) |
存储器访问指令
RV32I提供了按字节、半字和字访问存储器的8条指令。所有访存指令的寻址方式都是寄存器间接寻址方式,访存地址可以不对齐4字节边界,但是在实现中可以要求访存过程中对齐4字节边界。在读取单个字节或半字时,可以按要求对内存数据进行符号扩展或无符号扩展后再存入寄存器。 表 Fig. 76 列出了存储访问类指令的编码方式。 表 Table 15 列出了存储访问类指令的具体操作。
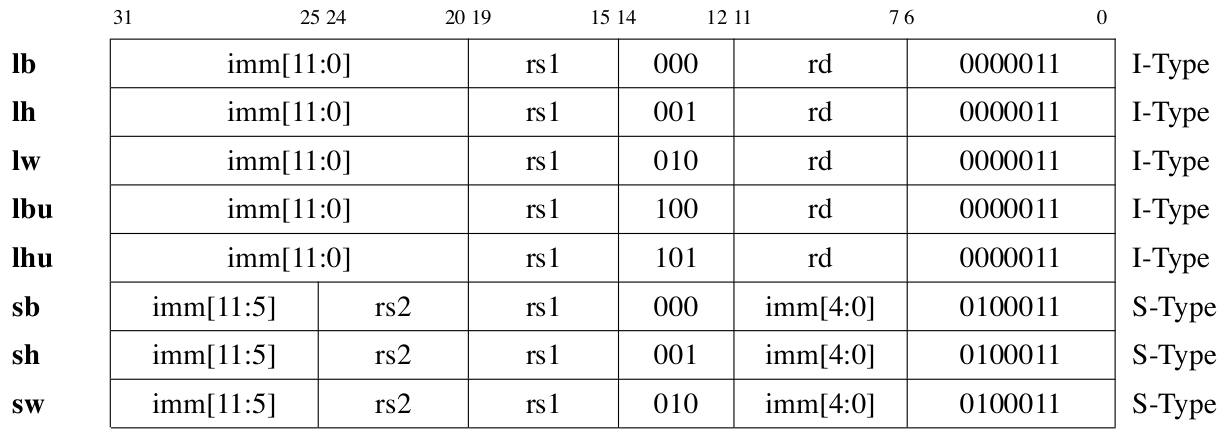
Fig. 76 RV32I 中存储访问指令编码列表
指令 |
操作 |
|---|---|
lb rd,imm12(rs1) |
|
lh rd,imm12(rs1) |
|
lw rd,imm12(rs1) |
|
lbu rd,imm12(rs1) |
|
lhu rd,imm12(rs1) |
|
sb rs2,imm12(rs1) |
|
sh rs2,imm12(rs1) |
|
sw rs2,imm12(rs1) |
|
常见伪指令
RISC-V中规定了一些常用的伪指令。这些伪指令一般可以在汇编程序中使用,汇编器会将其转换成对应的指令序列。表 Table 16 介绍了RISC-V的常见伪指令列表。
伪指令 |
实际指令序列 |
操作 |
|---|---|---|
nop |
addi x0, x0, 0 |
空操作 |
li rd,imm |
lui rd, imm[32:12]+imm[11]
addi rd, rd, imm[11:0]
|
加载32位立即数,先加载高位,
再加上低位,注意低位是符号扩展
|
mv rd, rs |
addi rd, rs |
寄存器拷贝 |
not rd, rs |
xori rd, rs, -1 |
取反操作 |
neg rd, rs |
sub rd, x0, rs |
取负操作 |
seqz rd, rs |
sltiu rd, rs, 1 |
等于0时置位 |
snez rd, rs |
sltu rd, x0, rs |
不等于0时置位 |
sltz rd, rs |
slt rd, rs, x0 |
小于0时置位 |
sgtz rd, rs |
slt rd, x0, rs |
大于0时置位 |
beqz rs, offset |
beq rs, x0, offset |
等于0时跳转 |
bnez rs, offset |
bne rs, x0, offset |
不等于0时跳转 |
blez rs, offset |
bge x0, rs, offset |
小于等于0时跳转 |
bgez rs, offset |
bge rs, x0, offset |
大于等于0时跳转 |
bltz rs, offset |
blt rs, x0, offset |
小于0时跳转 |
bgtz rs, offset |
blt x0, rs, offset |
大于0时跳转 |
bgt rs, rt, offset |
blt rt, rs, offset |
rs大于rt时跳转 |
ble rs, rt, offset |
bge rt, rs, offset |
rs小于等于rt时跳转 |
bgtu rs, rt, offset |
bltu rt, rs, offset |
无符号rs大于rt时跳转 |
bleu rs, rt, offset |
bgeu rt, rs, offset |
无符号rs小于等于rt时跳转 |
j offset |
jal x0, offset |
无条件跳转,不保存地址 |
jal offset |
jal x1, offset |
无条件跳转,地址缺省保存在x1 |
jr rs |
jalr x0, 0 (rs) |
无条件跳转到rs寄存器,不保存地址 |
jalr rs |
jalr x1, 0 (rs) |
无条件跳转到rs寄存器,地址缺省保存在x1 |
ret |
jalr x0, 0 (x1) |
函数调用返回 |
call offset |
aupic x1, offset[32:12]+offset[11]
jalr x1, offset[11:0] (x1)
|
调用远程子函数 |
la rd, symbol |
aupic rd, delta[32:12]+delta[11]
addi rd, rd, delta[11:0]
|
载入全局地址,其中detla是PC和全局符号地址的差 |
lla rd, symbol |
aupic rd, delta[32:12]+delta[11]
addi rd, rd, delta[11:0]
|
载入局部地址,其中detla是PC和局部符号地址的差 |
l{b|h|w} rd, symbol |
aupic rd, delta[32:12]+delta[11]
l{b|h|w} rd, delta[11:0] (rd)
|
载入全局变量 |
s{b|h|w} rd, symbol, rt |
aupic rd, delta[32:12]+delta[11]
s{b|h|w} rd, delta[11:0] (rt)
|
载入局部变量 |
RV32I电路实现
单周期电路设计
在了解了RV32I指令集的指令体系结构(Instruction Set Architecture,ISA)之后,我们将着手设计CPU的微架构(micro architecture)。 同样的一套指令体系结构可以用完全不同的微架构来实现。不同的微架构在实现的时候只要保证程序员可见的状态,即PC、通用寄存器和内存等,在指令执行过程中遵守ISA中的规定即可。具体微架构的实现可以自由发挥。 在本实验中,我们首先来实现单周期CPU的微架构。所谓单周期CPU是指CPU在每一个时钟周期中需要完成一条指令的所有操作,即每个时钟周期完成一条指令。
每条指令的执行过程一般需要以下几个步骤:
取指令 :使用本周期新的PC从指令存储器中取出指令,并将其放入指令寄存器(IR)中
指令译码 :对取出的指令进行分析,生成本周期执行指令所需的控制信号,并计算下一条指令的地址
读取操作数 :从寄存器堆中读取寄存器操作数,并完成立即数的生成
运算 :利用ALU对操作数进行必要的运算
访问内存 :包括读取或写入内存对应地址的内容
寄存器写回 :将最终结果写回到目的寄存器中
每条指令执行过程中的以上几个步骤需要CPU的控制通路和数据通路配合来完成。 其中控制通路主要负责控制信号的生成,通过控制信号来指示数据通路完成具体的数据操作。 数据通路是具体完成数据存取、运算的部件。 控制通路和数据通路分离的开发模式在数字系统中经常可以碰到。其设计的基本指导原则是:控制通路要足够灵活,并能够方便地修改和添加功能,控制通路的性能和时延往往不是优化重点。 反过来,数据通路需要简单且性能强大。数据通路需要以可靠的方案,快速地移动和操作大量数据。 在一个简单且性能强大的数据通路支持下,控制通路可以灵活地通过控制信号的组合来实现各种不同的应用。
图 Fig. 77 提供了RV32I单周期CPU的参考设计,下面我们就针对该CPU的控制通路和数据通路来分别进行说明。
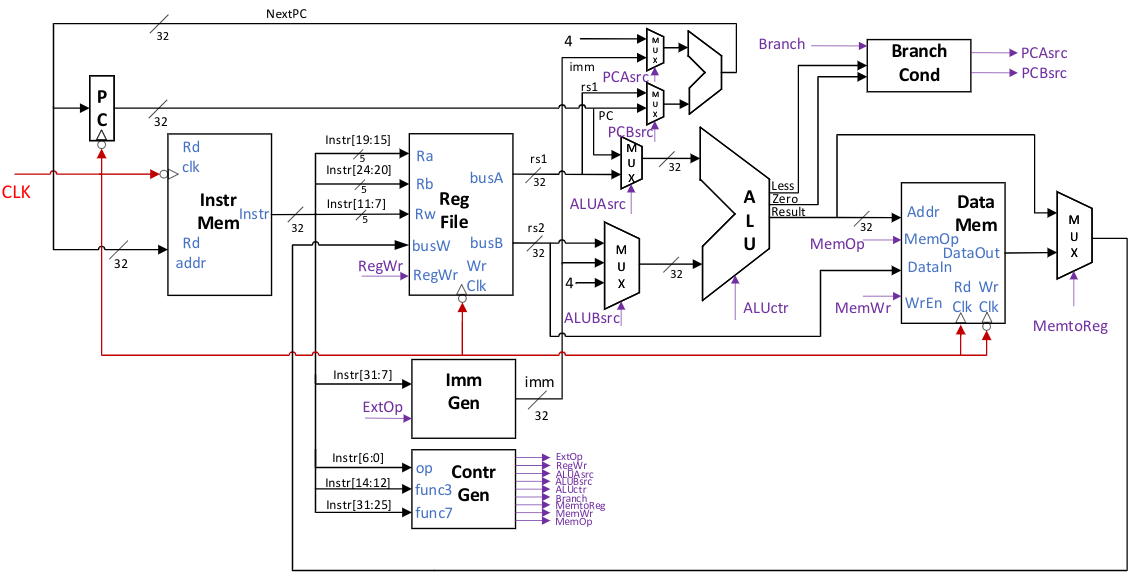
Fig. 77 单周期CPU的电路图
控制通路
PC生成
程序计数器PC控制了整个CPU指令执行的顺序。在顺序执行的条件下,下一周期的PC为本周期PC+4。如果发生跳转,PC将会变成跳转目标地址。 本设计中每个时钟周期是以时钟信号CLK的下降沿为起点的。在上一周期结束前,利用组合逻辑电路生成本周期将要执行的指令的地址NextPC。 在时钟下降沿到达时,将NEXT PC同时加载到PC寄存器和指令存储器的地址缓冲中去,完成本周期指令执行的第一步。 NextPC的计算涉及到指令译码和跳转分析,后续在 跳转控制 节中会详细描述。 在系统reset或刚刚上电时,可以将PC设置为固定的地址,如全零,让系统从特定的启动代码开始执行。
指令存储器
指令寄存器Instruction Memory专门用来存放指令。虽然在冯诺伊曼结构中指令和数据是存放在统一的存储器中,但大多数现代CPU是将指令缓存和数据缓存分开的。在本实验中我们也将指令和数据分开存储。 本实验中的指令存储器类似CPU中的指令缓存,采用FPGA中的SRAM来实现。由于DE10-Standard开发板上的大容量SRAM只支持在沿上进行读写,所以本设计采用时钟下降沿来对指令存储器进行读取操作,指令存储器的读取地址是NextPC。 指令存储器只需要支持读操作,在本实验中,可以要求所有代码都是4字节对齐,即PC低两位可以认为总是2’b00。由于指令存储器每次总是读取4个字节,所以可以将存储器的每个单元大小设置为32bit。 指令存储器可以使用单端口RAM来实现,总容量一般可以设置为256KB(64K条指令),可以满足大部分演示代码的需求。 指令存储器可以用mif文件来进行初始化,mif文件可以用实验指导提供的工具链生成。如果指令存储器生成是选择了In System Memory动态SRAM内容更新的功能,可以不用编译整个工程,直接在Quartus中加载新的代码。
ExtOP |
立即数类型 |
|---|---|
000 |
immI |
001 |
immU |
010 |
immS |
011 |
immB |
100 |
immJ |
指令译码及立即数生成
在读取出本周期的指令instr[31:0]之后,CPU将对32bit的指令进行译码,并产生各个指令对应的立即数。 RV32I的指令比较规整,所以可以直接取指令对应的bit做为译码结果:
assign op = instr[6:0];
assign rs1 = instr[19:15];
assign rs2 = instr[24:20];
assign rd = instr[11:7];
assign func3 = instr[14:12];
assign func7 = instr[31:25];
同样的,也可以利用立即数生成器imm Generator生成所有的立即数。注意,所有立即数均是符号扩展,且符号位总是instr[31]:
assign immI = {{20{instr[31]}}, instr[31:20]};
assign immU = {instr[31:12], 12'b0};
assign immS = {{20{instr[31]}}, instr[31:25], instr[11:7]};
assign immB = {{20{instr[31]}}, instr[7], instr[30:25], instr[11:8], 1'b0};
assign immJ = {{12{instr[31]}}, instr[19:12], instr[20], instr[30:21], 1'b0};
在生成各类指令的立即数之后,根据控制信号ExtOP,通过多路选择器来选择立即数生成器最终输出的imm是以上五种类型中的哪一个。 控制信号ExtOP为3bit,可以按表 Table 17 方式编码,未列出的编码可视为无关。
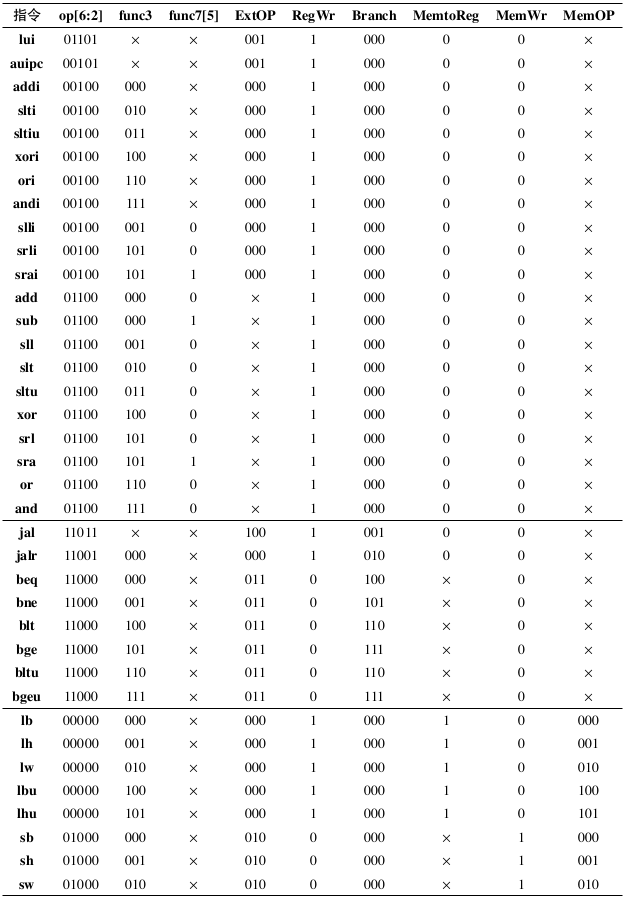
Fig. 78 RV32I指令控制信号列表第一部分
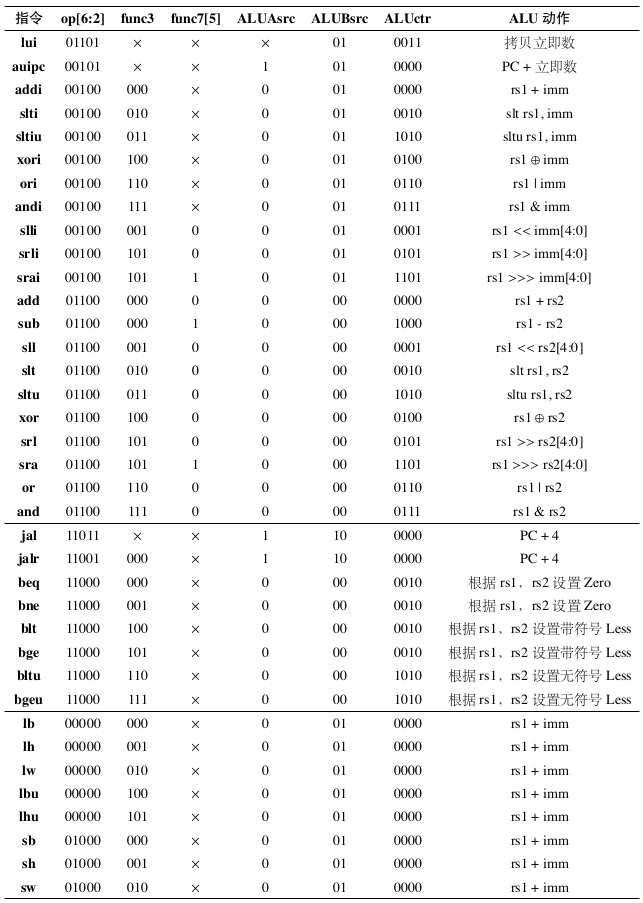
Fig. 79 RV32I指令控制信号列表第二部分
控制信号生成
在确定指令类型后,需要生成每个指令对应的控制信号,来控制数据通路部件进行对应的动作。控制信号生产部件(Control Signal Generator)是根据instr中的操作码opcode,及func3和func7来生成对应的控制信号的。 其中操作码实际只有高5位有用,func7实际只有次高位有用。 生成的控制信号具体包括:
ExtOP :宽度为3bit,选择立即数产生器的输出类型,具体含义参见表 Table 17 。
RegWr :宽度为1bit,控制是否对寄存器rd进行写回,为1时写回寄存器。
ALUAsrc :宽度为1bit,选择ALU输入端A的来源。为0时选择rs1,为1时选择PC。
ALUBsrc :宽度为2bit,选择ALU输入端B的来源。为00时选择rs2,为01时选择imm(当是立即数移位指令时,只有低5位有效),为10时选择常数4(用于跳转时计算返回地址PC+4)。
ALUctr :宽度为4bit,选择ALU执行的操作,具体含义参见表 Table 10 。
Branch :宽度为3bit,说明分支和跳转的种类,用于生成最终的分支控制信号,含义参见表 Table 18 。
MemtoReg :宽度为1bit,选择寄存器rd写回数据来源,为0时选择ALU输出,为1时选择数据存储器输出。
MemWr :宽度为1bit,控制是否对数据存储器进行写入,为1时写回存储器。
MemOP :宽度为3bit,控制数据存储器读写格式,为010时为4字节读写,为001时为2字节读写带符号扩展,为000时为1字节读写带符号扩展,为101时为2字节读写无符号扩展,为100时为1字节读写无符号扩展。
这些控制信号控制各个数据通路部件按指令的要求进行对应的操作。所有指令对应的控制信号列表如表 Fig. 78 和表 Fig. 79 所示。 根据这些控制信号可以得出系统在给定指令下的一个周期内所需要做的具体操作。 注意:这里的控制信号在定义上可能和教科书上的9条指令CPU控制信号有一些区别。 如果没有学习过组成原理的同学请参考相关教科书,分析各类指令在给定控制信号下的数据通路的具体操作。这里只进行一个简略的说明:
lui : ALU A输入端不用,B输入端为立即数,按U-Type扩展,ALU执行的操作是拷贝B输入,ALU结果写回到rd。
auipc :ALU A输入端为PC,B输入端为立即数,按U-Type扩展,ALU执行的操作是加法,ALU结果写回到rd。
立即数运算类指令 :ALU A输入端为rs1,B输入端为立即数,按I-Type扩展。ALU按ALUctr进行操作,ALU结果写回rd。
寄存器运算类指令 :ALU A输入端为rs1,B输入端为rs2。ALU按ALUctr进行操作,ALU结果写回rd。
jal : ALU A输入端PC,B输入端为常数4,ALU执行的操作是计算PC+4,ALU结果写回到rd。PC计算通过专用加法器,计算PC+imm,imm为J-Type扩展。
jalr : ALU A输入端PC,B输入端为常数4,ALU执行的操作是计算PC+4,ALU结果写回到rd。PC计算通过专用加法器,计算rs1+imm,imm为I-Type扩展。
Branch类指令 : ALU A输入端为rs1,B输入端为rs2,ALU执行的操作是比较大小或判零,根据ALU标志位选择NextPC,可能是PC+4或PC+imm,imm为B-Type扩展,PC计算由专用加法器完成。不写回寄存器。
Load类指令 :ALU A输入端为rs1,B输入端为立即数,按I-Type扩展。ALU做加法计算地址,读取内存,读取内存方式由存储器具体执行,内存输出写回rd。
Store类指令 :ALU A输入端为rs1,B输入端为立即数,按S-Type扩展。ALU做加法计算地址,将rs2内容写入内存,不写回寄存器。
跳转控制
代码执行过程中,NextPC可能会有多种可能性:
顺序执行:NextPC = PC + 4;
jal: NextPC = PC + imm;
jalr: NextPC = rs1 + imm;
条件跳转: 根据ALU的Zero和Less来判断,NextPC可能是PC + 4或者 PC + imm;
在设计中使用一个单独的专用加法器来进行PC的计算。同时,利用了跳转控制模块来生成加法器输入选择。其中,PCAsrc控制PC加法器输入A的信号,为0时选择常数4,为1时选择imm。 PCBsrc控制PC加法器输入B的信号,为0时选择本周期PC,为1时选择寄存器rs1。
跳转控制模块根据控制信号Branch和ALU输出的Zero及Less信号来决定PCASrc和PCBsrc。其中控制信号Branch的定义如表 Table 18 所示。 跳转控制模块的输出见表 Table 19 。
Branch |
跳转类型 |
|---|---|
000 |
非跳转指令 |
001 |
无条件跳转PC目标 |
010 |
无条件跳转寄存器目标 |
100 |
条件分支,等于 |
101 |
条件分支,不等于 |
110 |
条件分支,小于 |
111 |
条件分支,大于等于 |
Branch |
Zero |
Less |
PCAsrc |
PCBsrc |
NextPC |
|---|---|---|---|---|---|
000 |
\(\times\) |
\(\times\) |
0 |
0 |
PC + 4 |
001 |
\(\times\) |
\(\times\) |
1 |
0 |
PC + imm |
010 |
\(\times\) |
\(\times\) |
1 |
1 |
rs1 + imm |
100 |
0 |
\(\times\) |
0 |
0 |
PC + 4 |
100 |
1 |
\(\times\) |
1 |
0 |
PC + imm |
101 |
0 |
\(\times\) |
1 |
0 |
PC + imm |
101 |
1 |
\(\times\) |
0 |
0 |
PC + 4 |
110 |
\(\times\) |
0 |
0 |
0 |
PC + 4 |
110 |
\(\times\) |
1 |
1 |
0 |
PC + imm |
111 |
\(\times\) |
0 |
1 |
0 |
PC + imm |
111 |
\(\times\) |
1 |
0 |
0 |
PC + 4 |
数据通路
单周期数据通路可以复用上个实验中设计的寄存器堆、ALU和数据存储器,这里就不再详细描述。
单周期CPU的时序设计
在单周期CPU中,所有操作均需要在一个周期内完成。其中单周期存储部件的读写是时序设计的关键。在CPU架构中PC、寄存器堆,指令存储器和数据存储器都是状态部件,需要用寄存器或存储器来实现。 在实验五中,我们也看到,如果要求上述存储部件以非同步方式进行读写会消耗大量资源,无法实现大容量的存储。因此,需要仔细地规划各个存储器的读写时序和实现方式。
图 Fig. 80 描述了本实验建议的时序设计方案。在该设计中,PC和寄存器堆由于容量不大,可以采用非同步方式读取,即地址改变后立即输出对应的数据。 对指令存储器和数据存储器来说,一般系统至少需要数百KB的容量。此时建议用时钟沿来控制读写。假定我们是以时钟下降延为每个时钟周期的开始。对于存储器和寄存器的写入统一安排在下降沿上进行。 对于数据存储器的读出,由于地址计算有一定延时,可以在时钟上升沿进行读取。
下面通过图 Fig. 80 来描述单个时钟周期内CPU的具体动作。其中绿色部分为本周期正确数据,黄色为上一周期的旧数据,蓝色为下一周期的未来数据。
周期开始的下降沿将同时用于写入PC寄存器和读取指令存储器。由于指令存储器要在下降沿进行读取操作,而PC的输出要等到下降沿后才能更新,所以不能拿PC的输出做为指令存储器的地址。可以采用PC寄存器的输入,NextPC来做为指令存储器的地址。该信号是组合逻辑,一般在上个周期末就已经准备好。
指令读出后将出现在指令存储器的输出端,该信号可以通过组合逻辑来进行指令译码,产生控制信号,寄存器读写地址及立即数等。
寄存器读地址产生后,直接通过非同步读取方式,读取两个源寄存器的数据,与立即数操作数一起准备好,进入ALU的输入端。
ALU也是组合逻辑电路,在输入端数据准备好后就开始运算。由于数据存储器的读取地址也是ALU来计算的,所以要求ALU输出结果能在时钟半个周期的上升沿到来之前准备好。
时钟上升沿到来的时候,数据存储器的读地址如果准备好了,就可以在上升沿进行内存读取操作。
最后,在下一周期的时钟下降沿到来的时候,同时对目的寄存器和数据存储器进行写入操作。这样下一周期这些存储器中的数据就是最新的了。
实验采用的DE10-Standard开发板上的M10K支持读写时钟分离的ram,且能够在主时钟50MHz下进行单周期读写操作。在此时序设计下,主要的关键路径在Load指令的读取地址生成,该路径需要在半个周期内完成,如果出现时序无法满足的情况,可以考虑降低时钟频率。
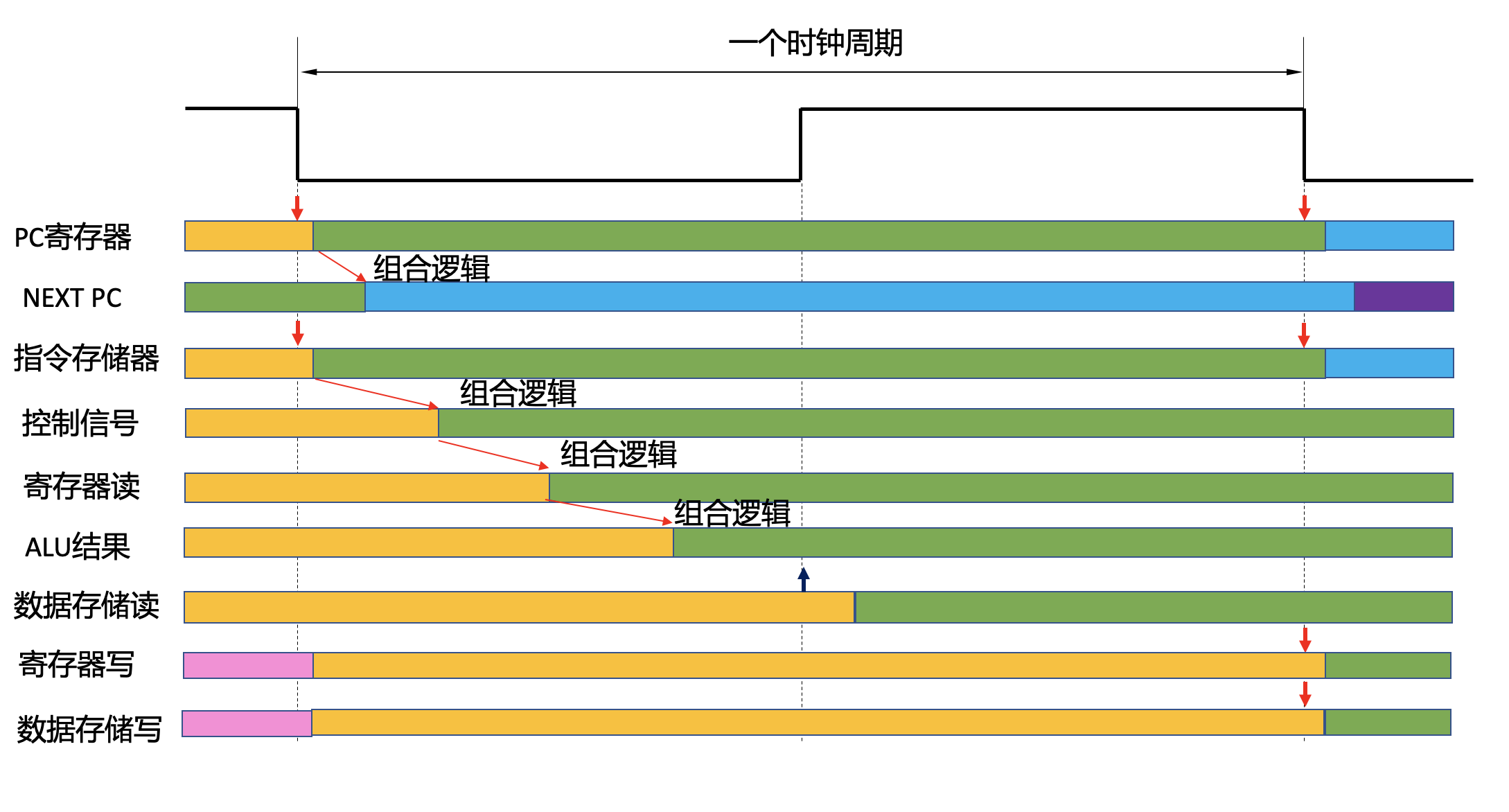
Fig. 80 单周期CPU的时序设计
模块化设计
CPU设计过程中需要多个不同的模块分工协作,建议在开始编码前划分好具体模块的功能和接口。对于模块划分我们提供了以下的参考建议。顶层实体内包含的模块主要是:
CPU模块 :主要对外接口包括时钟、Reset、指令存储器的地址/数据线、数据存储器的地址及数据线和自行设计的调试信号。
ALU模块:主要对外接口是ALU的输入操作数、ALU控制字、ALU结果输出和标志位输出等。
加法器模块
桶型移位器模块
寄存器堆模块:主要对外接口是读写寄存器号输入、写入数据输入、寄存器控制信号、写入时钟、输出数据。
控制信号生成模块:主要对外接口是指令输入及各种控制信号输出。
立即数生成器模块:主要对外接口是指令输入,立即数类型及立即数输出。
跳转控制模块:主要对外接口是ALU标志位输入、跳转控制信号输入及PC选择信号输出。
PC生成模块:主要对外接口是PC输入、立即数输入,rs1输入,PC选择信号及NEXTPC输出。
指令存储器模块 :主要对外接口包括时钟、地址线和输出数据线。
数据存储器模块 :主要对外接口包括时钟、输入输出地址线、输入输出数据、内存访问控制信号和写使能信号。
外围设备 :用于Reset或显示调试结果等等。
以上模块划分不是唯一的,同学们可以按照自己的理解进行划分。 设计中将存储器部分与CPU分开放在顶层的主要目的是在后续的计算机系统实验中简化外设对存储器的访问。 设计时请先划分模块,确认模块的连接,再单独开发各个模块,建议对模块进行单元测试后再整合系统。
软件及测试部分
RISC-V CPU是一个较为复杂的数字系统,在开发过程中需要对每一个环节进行详细的测试才能够保证系统整体的可靠性。
单元测试
在开发过程中,需要首先确保每一个子单元都正常工作,因此在完成各个单元的代码编写后需要进行对应的测试。具体可以包括:
代码复查 :检查代码编写过程中是否有问题,尤其是变量名称、数据线宽度等易出错的地方。检查编译中的警告,判断是否警告会带来错误。
RTL复查 :利用RTL Viewer检查系统编译输出的RTL是否符合设计构想,有没有悬空或未连接的引脚。
TestBench功能仿真 :通过针对独立单元的testbench进行功能仿真,尤其需要注意ALU、寄存器堆、及内容的功能正确性。对于存储元件需要分析时序正确性,即数据是否在正确的时间给出,写入时是否按预期写入等。
单步功能仿真
在完成基本单元测试后,可以进行CPU整体的联调。整体联调的主要目的是验证各个指令基本功能的正确性。 实验指导提供了testbench的示例帮助大家进行单步指令的执行和验证。
在这个Testbench中,首先定义了一部分测试中需要用到的变量:
`timescale 1 ns / 10 ps
module testbench_cpu();
integer numcycles; //number of cycles in test
reg clk,reset; //clk and reset signals
reg[8*30:1] testcase; //name of testcase
其中testcase是我们的测试用例名,为字符串格式,用来载入不同的测试用例。
随后,在testbench中实例化CPU中的部件,这里单独实例化了CPU主体、指令存储和数据存储:
// CPU declaration
// signals
wire [31:0] iaddr,idataout;
wire iclk;
wire [31:0] daddr,ddataout,ddatain;
wire drdclk, dwrclk, dwe;
wire [2:0] dop;
wire [23:0] cpudbgdata;
//main CPU
rv32is mycpu(.clock(clk),
.reset(reset),
.imemaddr(iaddr), .imemdataout(idataout), .imemclk(iclk),
.dmemaddr(daddr), .dmemdataout(ddataout), .dmemdatain(ddatain),
.dmemrdclk(drdclk), .dmemwrclk(dwrclk), .dmemop(dop), .dmemwe(dwe),
.dbgdata(cpudbgdata));
//instruction memory, no writing
testmem instructions(
.address(iaddr[17:2]),
.clock(iclk),
.data(32'b0),
.wren(1'b0),
.q(idataout));
//data memory
dmem datamem(.addr(daddr),
.dataout(ddataout),
.datain(ddatain),
.rdclk(drdclk),
.wrclk(dwrclk),
.memop(dop),
.we(dwe));
在实际实现中请同学们根据自己设计的CPU接口自行进行更改。在测试过程中,建议可以用自己写的memory模块替代IP核生成的memory模块,方便对内存进行各类操作。
随后,定义了一系列的辅助task,帮助我们完成各类测试操作:
//useful tasks
task step; //step for one cycle ends 1ns AFTER the posedge of the next cycle
begin
#9 clk=1'b0;
#10 clk=1'b1;
numcycles = numcycles + 1;
#1 ;
end
endtask
task stepn; //step n cycles
input integer n;
integer i;
begin
for (i =0; i<n ; i=i+1)
step();
end
endtask
task resetcpu; //reset the CPU and the test
begin
reset = 1'b1;
step();
#5 reset = 1'b0;
numcycles = 0;
end
endtask
其中step任务是将CPU时钟前进一个周期,在单周期CPU中等价于单步执行一条指令。注意我们这里的周期是以上升沿开始的,在实际测试中可以将时间步进到下一个周期的上升沿后一个时间单位,这主要是由于我们单周期CPU是在下一上升沿进行写入,对数据的验证要在上升沿略后一些的时间进行。 stepn任务用于执行n条指令,resetcpu用于将cpu重置,从预定开始执行的地址重新执行。
Testbench中还定义了载入任务:
task loadtestcase; //load intstructions to instruction mem
begin
$readmemh({testcase, ".hex"},instructions.ram);
$display("---Begin test case %s-----", testcase);
end
endtask
该任务用于载入指令文件。指令文件为文本格式,建议放在simulate/modelsim子目录下,用相对目录名来定位文件。 这里采用$readmemh读入到指定的指令存储中去,由于指令存储空间的声明不在顶层实体instructions中,需要使用instructions.ram来访问实体内部声明的变量ram。 在编写testbench时请同学们自己按照自己的设计来定位实际应该访问的变量的位置。
同时还需要定义一系列的断言任务,辅助检查寄存器或者内存中的内容,并在出错时提供提示信息:
task checkreg;//check registers
input [4:0] regid;
input [31:0] results;
reg [31:0] debugdata;
begin
debugdata=mycpu.myregfile.regs[regid]; //get register content
if(debugdata==results)
begin
$display("OK: end of cycle %d reg %h need to be %h, get %h",
numcycles-1, regid, results, debugdata);
end
else
begin
$display("!!!Error: end of cycle %d reg %h need to be %h, get %h",
numcycles-1, regid, results, debugdata);
end
end
endtask
在这个任务中访问了CPU内部定义的寄存器堆myregfile中的regs变量,并根据所需要的访问regid来提取数据,并和预期数据进行比较。 如果不正确,任务会提示比较结果,方便进行debug。 同样的,也可以编写类似的内存内容比较模块,对内存中的内容进行检查。
假定需要测试CPU中加法语句的正确性,同学们可以编写一小段汇编
addi t1,zero,100
addi t2,zero,20
add t3,t1,t2
在这段汇编执行过程中,我们可以检查各个寄存器结果,观察代码执行的正确性。 利用上学期用过的 rars 仿真器来将这段汇编转换为二进制,并写入add.hex文件中,无需添加文件头v2.0 raw。示例文件的具体内容如下:
06400313
01400393
00730E33
Testbench具体的执行部分如下:
initial begin:TestBench
#80
// output the state of every instruction
$monitor("cycle=%d, pc=%h, instruct= %h op=%h,
rs1=%h,rs2=%h, rd=%h, imm=%h",
numcycles, mycpu.pc, mycpu.instr, mycpu.op,
mycpu.rs1,mycpu.rs2,mycpu.rd,mycpu.imm);
testcase = "add";
loadtestcase();
resetcpu();
step();
checkreg(6,100); //t1==100
step();
checkreg(7,20); //t2=20
step();
checkreg(28,120); //t3=120
$stop
end
执行过程中,首先使用$monitor来定义我们需要观察的变量,只要这些变量发生变化modelsim会自动地打印出变量的内容。 这样,可以在每条指令执行时看到对应的PC及指令解码的关键信息。同学们也可以自定义需要观察的信号。 在载入add测试用例后,testbench单步执行了3次,每次执行完就按照我们预期的执行结果检查了t1, t2和t3寄存器。 modelsim的实际输出如图 Fig. 81 :
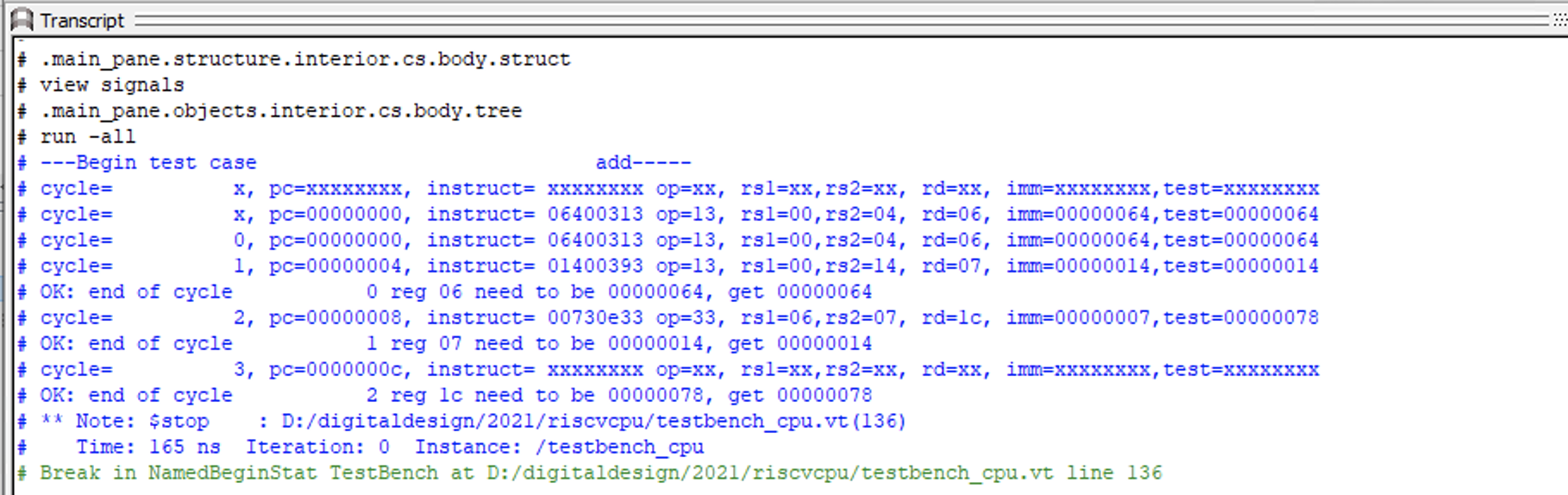
Fig. 81 单周期CPU的仿真输出
从图中可以看到初始化结束后代码从全零地址开始执行,每个周期结束后会对寄存器进行检查。注意这里检查点在上升沿到来后,所以在第n周期结束时,PC和指令已经是下一条指令的内容了。
请自行按照自己的设计修改单步仿真testbench,并自行设计测试用例来对CPU进行初步联调。
系统功能仿真
单步功能仿真用于简单验证CPU中各条指令的基本情况,确保CPU可以完成基础功能。 但是,为了排除CPU中潜在的bug,我们需要对CPU的实现进行详细的测试,避免后面在搭建整个计算机系统时由于CPU的问题出现难以定位的bug。 在本实验中使用RISC-V的官方测试集来对CPU进行全面的系统仿真。
riscv-tests测试集简介
RISC-V社区开发了 官方测试集 ,针对不同的RISC-V指令变种都提供了测试。 测试集的编译需要安装risc-v gcc工具链,在Ubuntu下运行
apt-get install g++-riscv64-linux-gnu binutils-riscv64-linux-gnu
如果在编译时遇到问题,可以参考PA2.2中的 解决方法 。 我们将测试移植到了AM中,地址为 https://github.com/NJU-ProjectN/riscv-tests.git 。如果要使用该测试集,可以运行下列命令
$ git clone -b digit https://github.com/NJU-ProjectN/riscv-tests.git
$ git clone -b digit https://github.com/NJU-ProjectN/abstract-machine.git
$ export AM_HOME=$(pwd)/abstract-machine
$ cd riscv-tests
$ make
其中第1-2句从github上下载riscv-tests和am源代码,第3句设置环境变量,最后编译测试集。 编译后的文件在riscv-tests/build目录下,包括可执行文件(.elf)和反汇编文件(.txt),以及我们需要的FPGA内存hex文件和mif文件。大家可以在反汇编文件中查看测试用例中包含的指令以及每条指令的地址。
RISC-V 官方测试集针对不同的 RISC-V 指令变种都提供了测试。在本实验中,我们主要使用 rv32ui 也就是 RV32 的基本指令集, u 表示是用户态, i 表示是整数基本指令集。实验中采用的环境是无虚拟地址的环境,即只使用物理地址访问内存。
测试程序移植
AM为应用程序提供了裸机运行时环境,最简单的运行时环境如abstract-machine/src/npc目录下的start.S和trm.c所示。 AM设置了栈指针、程序的入口(main)以及退出程序的方式(halt),在完成初始化后就跳转到应用程序,也就是riscv-tests中的目标测试继续执行。
riscv-tests中提供了对每条指令的单元测试,以下为add测试用例中的部分反汇编片段:
00000580 <test_38>:
580: 01000093 li ra,16
584: 01e00113 li sp,30
588: 00208033 add zero,ra,sp
58c: 00000393 li t2,0
590: 02600193 li gp,38
594: 00701463 bne zero,t2,59c <fail>
598: 00301863 bne zero,gp,5a8 <pass>
0000059c <fail>:
59c: deade537 lui a0,0xdeade
5a0: ead50513 addi a0,a0,-339 # deaddead <_pmem_start+0x5eaddead>
5a4: 0200006f j 5c4 <halt>
000005a8 <pass>:
5a8: 00c10537 lui a0,0xc10
5ac: fee50513 addi a0,a0,-18 # c0ffee <_end+0xb0f7ee>
5b0: 0140006f j 5c4 <halt>
在这里,程序会检查两个数的加法运算是否为预期结果,并相应地跳转到fail或者pass中。 在pass中会调用halt,将a0寄存器的值设置为32’h00c0ffee,并放入一条指令32’hdead10cc,表示测试完成,在仿真中获取这个数字之后就可以判断仿真完成了。 如果是fail的情况,则将a0置为32’hdeaddead,随后停止仿真。在仿真结束时通过a0寄存器的值就可以判断是否通过了全部测试。
特殊指令32’hdead10cc
为什么正常的 rv32i 指令序列中肯定不会出现 32’hdead10cc ?在反汇编文件中,32’hdead10cc被反汇编成了什么?
在编译生成可执行文件后,得到的elf文件并不能直接用于FPGA内存初始化。所以,我们需要自动生成针对 verilog 的文本 .hex 文件和对 IP 核初始化的mif 文件。 在完成编译后会自动执行abstract-machine/scripts/riscv32-npc.mk中的以下命令,生成需要载入FPGA的hex文件:
RISCV_OBJCOPY ?= $(RISCV_PREFIX)objcopy -O verilog
RISCV_HEXGEN ?= 'BEGIN{output=0;}{ gsub("\r","",$$(NF)); if ($$1~/@/) {if ($$1 ~/@80000000/) {output=code;} else {output=1-code;}; gsub("@","0x",$$1); addr=strtonum($$1); if (output==1){printf "@%08x\n",(addr%262144)/4;}} else {if (output==1) {for(i=1;i<NF;i+=4) print $$(i+3)$$(i+2)$$(i+1)$$i;}}}'
RISCV_MIFGEN ?= 'BEGIN{printf "WIDTH=32;\nDEPTH=%d;\n\nADDRESS_RADIX=HEX;\nDATA_RADIX=HEX;\n\nCONTENT BEGIN\n",depth; addr=0;} { gsub("\r","",$$(NF)); if ($$1 ~/@/) {gsub("@","0x",$$1);addr=strtonum($$1);} else {printf "%04X : %s;\n",addr, $$1; addr=addr+1;}} END{print "END\n";}'
image: $(IMAGE).elf
@$(OBJDUMP) -d $(IMAGE).elf > $(IMAGE).txt
$(RISCV_OBJCOPY) $< $(IMAGE).tmp
awk -v code=1 $(RISCV_HEXGEN) $(IMAGE).tmp > $(IMAGE).hex
awk -v code=0 $(RISCV_HEXGEN) $(IMAGE).tmp > $(IMAGE)_d.hex
awk -v depth=65536 $(RISCV_MIFGEN) $(IMAGE).hex > $(IMAGE).mif
awk -v depth=32768 $(RISCV_MIFGEN) $(IMAGE)_d.hex > $(IMAGE)_d.mif
该过程分为以下几步: 首先用反汇编工具objdump生成包含所有指令的文本文件,方便进行测试。 第二步用 objcopy 工具来生成 .tmp 文件,这个文件符合 verilog 格式要求,但是其中的数据是按 8bit 字节存储的,无法直接用于初始化 32bit 宽度的内存。 第三步(line 8-9)是用 linux 的 awk 文本处理工具简单转换一下 verilog 的格式。 awk的指令请自行查找资料学习。本例中 awk 根据 output 变量判断是否需要打印输出。在读入一行后首先去除了最后一个 token 的换行符,然后判断是否是以 @开头的地址。如果是,则判断地址是否是 0x80000000 代码段起始地址。根据变量 code 来判断是生成代码初始化文件还是数据初始化文件。随后,对地址取低18 位,并将地址除以四(从 byte 编址改成我们存储器中 4 字节编址),并打印修改后的地址。对于正常的数据行,awk会将token分成四个一组重新打印。
思考
为什么我们将起始为 0x80000000 的代码段和数据段地址只取低 18位来生成代码和数据存储器的初始化文件,我们的 CPU 仍然正确地执行并找到对应的数据?
第四步(line 10-11)是用awk将文本hex格式改成mif格式,增加文件头尾和地址标识。
思考
如果数据存储器是用 4 片 8bit 存储器来实现的,如何生成 4 片存储器对应的初始化文件?
采用上面介绍的框架和方法,我们能够很容易地移植其他测试程序,以一个简单的求和运算为例:
//sum.c
#define PASS_CODE 0xc0ffee
#define FAIL_CODE 0xdeaddead
void halt(int code);
__attribute__((noinline))
void check(int cond) {
if (!cond) halt(FAIL_CODE);
}
int main() {
int i = 1;
volatile int sum = 0;
while(i <= 100) {
sum += i;
i ++;
}
check(sum == 5050);
return PASS_CODE;
}
并编写相应Makefile文件,我们提供了一个简单的Makefile实例如下:
// Makefile
.PHONY: all clean $(ALL)
ARCH ?= riscv32-npc
ALL ?= sum
all: $(addprefix Makefile-, $(ALL))
@echo "" $(ALL)
$(ALL): %: Makefile-%
Makefile-%: %.c
@/bin/echo -e "NAME = $*\nSRCS = $<\nLIBS += klib\nINC_PATH += $(shell pwd)/env/p $(shell pwd)/isa/macros/scalar\ninclude $${AM_HOME}/Makefile" > $@
-@make -s -f $@ ARCH=$(ARCH) $(MAKECMDGOALS)
-@rm -f Makefile-$*
clean:
rm -rf Makefile-* build/
通过变量ALL指定需要编译的程序源文件,并使用AM中的Makefile,将应用程序、运行时环境和AM中定义的库函数一起编译成可执行文件,同学们可以阅读AM中的Makefile了解编译具体过程,也可以自行编写Makefile进行编译。 在设置好环境变量AM_HOME后,在该目录下通过make命令编译后,就能够在build目录下找到相应的文件。这样就能够自己编写更多的测试用例来测试处理器的实现。
测试集TestBench
我们需要修改Testbench支持对官方测试集的仿真。主要增加了以下辅助任务:
integer maxcycles =10000;
task run;
integer i;
begin
i = 0;
while( (mycpu.instr!=32'hdead10cc) && (i<maxcycles))
begin
step();
i = i+1;
end
end
endtask
代码运行任务run会一直用单步运行代码,直到遇到我们定义的代码终止信号为止。如果代码一直不终止也会在给定最大运行周期后停止仿真。
对仿真结果测试是通过对仿真结束后a0寄存器中数据是否符合预期来进行判断的。当然如果程序不终止,或者a0数据不正常也会报错。
task checkmagnum;
begin
if(numcycles>maxcycles)
begin
$display("!!!Error:test case %s does not terminate!", testcase);
end
else if(mycpu.myregfile.regs[10]==32'hc0ffee)
begin
$display("OK:test case %s finshed OK at cycle %d.",
testcase, numcycles-1);
end
else if(mycpu.myregfile.regs[10]==32'hdeaddead)
begin
$display("!!!ERROR:test case %s finshed with error in cycle %d.",
testcase, numcycles-1);
end
else
begin
$display("!!!ERROR:test case %s unknown error in cycle %d.",
testcase, numcycles-1);
end
end
endtask
数据存储可以用我们生成的hex文件进行初始化,仿真时可以用我们提供的ram模块替代IP核生成的模块。一般只有在访存指令的测试时才需要初始化数据存储
task loaddatamem;
begin
$readmemh({testcase, "_d.hex"},datamem.mymem.ram);
end
endtask
我们也提供了一个简单的可以执行单个测试用例的任务
task run_riscv_test;
begin
loadtestcase();
loaddatamem();
resetcpu();
run();
checkmagnum();
end
endtask
所以在仿真过程中我们只需要按顺序执行所有需要的仿真即可:
testcase = "rv32ui-p-simple";
run_riscv_test();
testcase = "rv32ui-p-add";
run_riscv_test();
testcase = "rv32ui-p-addi";
run_riscv_test();
testcase = "rv32ui-p-and";
run_riscv_test();
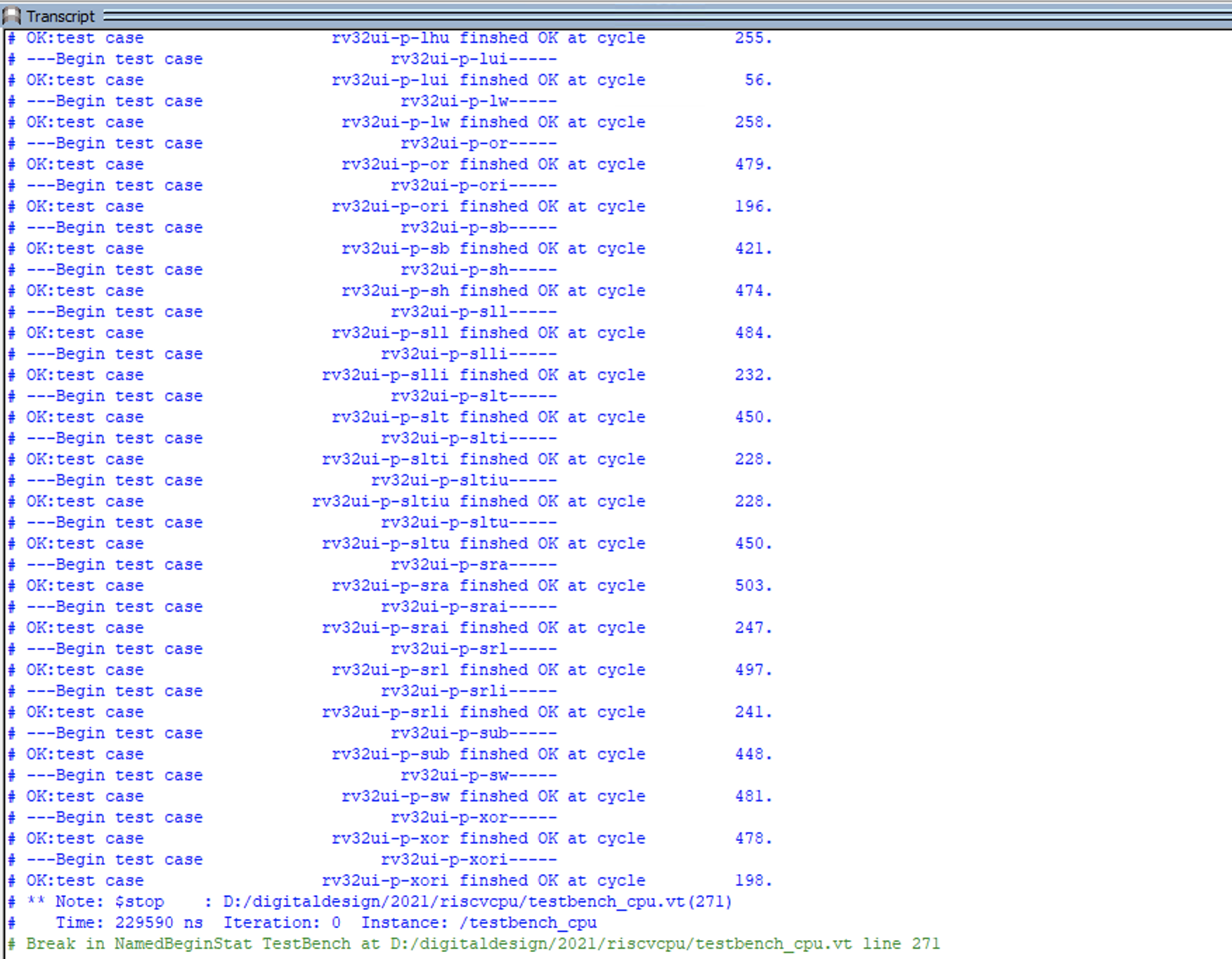
Fig. 82 使用官方测试集的CPU的仿真输出
在仿真过程中可以暂时注释$monitor任务,只有在出错时再检查具体测试用例为何出错。图 Fig. 82 显示了利用官方测试集进行仿真的输出结果示例。
上板测试
在设计过程中建议CPU预留测试数据接口,上板测试前可以将对应接口接至板上的LED或七段数码管,显示CPU的内部状态。具体选择测试接口输出哪些内容可以自行决定,可以考虑PC、寄存器结果,控制信号等等。 在初次上板测试时,可以将CPU时钟连接到板载的KEY按钮上,每按一下单步执行一个周期,方便进行调试。
对于单周期CPU,由于需要在一个周期内完成指令执行的所有步骤,很可能不能以50MHz运行。请观察你的CPU综合后Timing Analysis结果是否存在时序不满足,即某些model下Setup Slack为负数。此时,可以考虑调整设计减少关键路径时延,或者降低主频。
实验验收要求
在线测试
请自行完成单周期CPU的实现,并通过在线测试中单周期CPU的功能测试及官方测试部分。
必做 单周期功能测试
必做 单周期CPU官方测试