甩锅声明
从PA4开始, 讲义中就不再提供滴水不漏的代码指导了, 部分关键的代码细节需要你自己去思考和尝试(我们故意省略的). 我们会在讲义中将技术的原理阐述清楚, 你需要首先理解这些原理, 然后根据理解来阅读并编写相应的代码.
一句话总结, 与其抱怨讲义写得不清楚, 还不如自己多多思考. 现在都到PA4了, 为了让成绩符合正态分布, 拿高分总需要多付出点努力吧. 如果你之前都是想办法投机取巧而不去深入理解系统如何工作, 现在应该已经没戏了.
多道程序
通过Nanos-lite的支撑, 我们已经在NEMU中成功运行了一个批处理系统, 并把仙剑奇侠传跑起来了! 这说明我们亲自构建的NEMU这个看似简单的机器, 同样能支撑真实程序的运行, 丝毫不逊色于真实的机器! 不过, 这个批处理系统目前还是只能同时运行一个程序, 只有当一个程序结束执行之后, 才会开始执行下一个程序.
这也正是批处理系统的一个缺陷: 如果当前程序正在等待输入输出, 那么整个系统都会因此而停顿. 在真实的计算机中, 和CPU的性能相比, 输入输出是非常缓慢的: 以磁盘为例, 磁盘进行一次读写需要花费大约5毫秒的时间, 但对于一个2GHz的CPU来说, 它需要花费10,000,000个周期来等待磁盘操作的完成. 但事实上, 与其让系统陷入无意义的等待, 还不如用这些时间来进行一些有意义的工作. 一个简单的想法就是, 在系统一开始的时候加载多个程序, 然后运行第一个; 当第一个程序需要等待输入输出的时候, 就切换到第二个程序来运行; 当第二个程序也需要等待的时候, 就继续切换到下一个程序来运行, 如此类推.
这就是多道程序(multiprogramming)系统的基本思想. 多道程序的想法听上去很简单, 但它也是一种多任务系统, 这是因为它已经包含了多任务系统的基本要素. 换句话说, 要把批处理的Nanos-lite改造成一个多道程序操作系统, 我们只需要实现以下两点就可以了:
- 在内存中可以同时存在多个进程
- 在满足某些条件的情况下, 可以让执行流在这些进程之间切换
术语变更
既然是多任务系统, 系统中就运行的程序就不止一个了. 现在我们就可以直接使用"进程"的概念了.
要实现第一点并不难, 我们只要让loader把不同的进程加载到不同的内存位置就可以了, 加载进程的过程本质上就是一些内存拷贝的操作, 因此并没有什么困难的地方.
其实我在骗你!
对我们目前实现的计算机系统来说, "把不同的进程加载到不同的内存位置"其实是一件很麻烦的事情, 你能想明白为什么吗? 如果想不明白也没关系, 我们会在下一阶段详细讨论这个问题.
为了简单起见, 我们可以在Nanos-lite中直接定义一些测试函数来作为程序, 因为程序本质上就是一些有意义的指令序列, 目前我们不必在意这些指令序列到底从何而来. 不过, 一个需要注意的地方是栈, 我们需要为每个进程分配各自的栈空间.
为什么需要使用不同的栈空间?
如果不同的进程共享同一个栈空间, 会发生什么呢?
反而需要深思熟虑的是第二点: 表面上看, "怎么让执行流在进程之间切换"并不是一件直观的事情.
上下文切换
在PA3中, 我们已经提到了操作系统和用户进程之间的执行流切换, 并介绍了"上下文"的概念: 上下文的本质就是进程的状态. 换句话说, 我们现在需要考虑的是, 如何在多个用户进程之间进行上下文切换.
基本原理
事实上, 有了CTE, 我们就有一种很巧妙的方式来实现上下文切换了.
具体地, 假设进程A运行的过程中触发了系统调用, 陷入到内核.
根据__am_asm_trap()的代码, A的上下文结构(Context)将会被保存到A的栈上.
在PA3中, 系统调用处理完毕之后, __am_asm_trap()会根据栈上保存的上下文结构来恢复A的上下文.
神奇的地方来了, 如果我们先不着急恢复A的上下文,
而是先将栈顶指针切换到另一个进程B的栈上, 那会发生什么呢?
由于B的栈上存放了之前B保存的上下文结构, 接下来的操作就会根据这一结构来恢复B的上下文.
从__am_asm_trap()返回之后, 我们已经在运行进程B了!
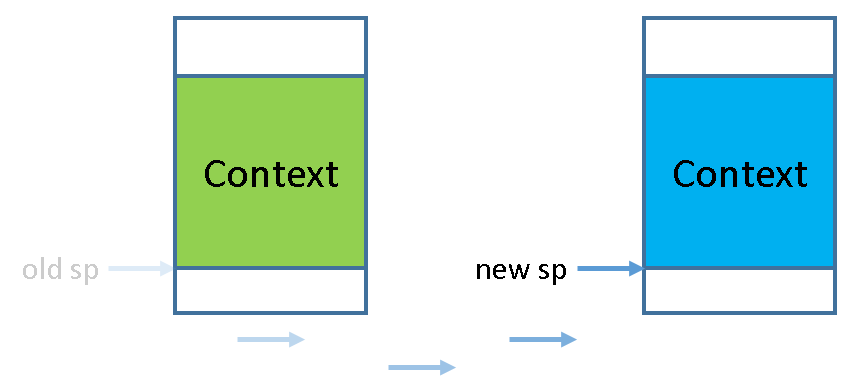
那进程A到哪里去了呢? 别担心, 它只是被暂时"挂起"了而已. 在被挂起之前, 它已经把上下文结构保存到自己的栈上了, 如果将来的某一时刻栈顶指针被切换到A的栈上, 代码将会根据栈上的上下文结构来恢复A的上下文, A将得以唤醒并执行. 所以, 上下文切换其实就是不同进程之间的栈切换!
进程控制块
但是, 我们要如何找到别的进程的上下文结构呢?
注意到上下文结构是保存在栈上的, 但栈空间那么大,
受到函数调用形成的栈帧的影响, 每次保存上下文结构的位置并不是固定的.
自然地, 我们需要一个cp指针(context pointer)来记录上下文结构的位置,
当想要找到其它进程的上下文结构的时候, 只要寻找这个进程相关的cp指针即可.
事实上, 有不少信息都是进程相关的,
除了刚才提到的上下文指针cp之外, 上文提到的栈空间也是如此.
为了方便对这些进程相关的信息进行管理,
操作系统使用一种叫进程控制块(PCB, process control block)的数据结构, 为每一个进程维护一个PCB.
Nanos-lite的框架代码中已经定义了我们所需要使用的PCB结构(在nanos-lite/include/proc.h中定义):
typedef union {
uint8_t stack[STACK_SIZE] PG_ALIGN;
struct {
Context *cp;
};
} PCB;
PCB中还定义了其它成员, 目前可以忽略它们, 我们会在将来介绍它们.
Nanos-lite使用一个联合体来把其它信息放置在进程堆栈的底部.
代码为每一个进程分配了一个32KB的堆栈, 已经足够使用了, 不会出现栈溢出导致UB.
在进行上下文切换的时候, 只需要把PCB中的cp指针返回给CTE的__am_irq_handle()函数即可,
剩余部分的代码会根据上下文结构恢复上下文.
我们只要稍稍借助数学归纳法, 就可以让我们相信这个过程对于正在运行的进程来说总是正确的.
那么, 对于刚刚加载完的进程, 我们要怎么切换到它来让它运行起来呢?
内核线程
创建内核线程上下文
答案很简单, 我们只需要在进程的栈上人工创建一个上下文结构, 使得将来切换的时候可以根据这个结构来正确地恢复上下文即可.
上文提到, 我们先把Nanos-lite中直接定义的一些测试函数作为程序.
Nanos-lite提供了一个测试函数hello_fun()(在nanos-lite/src/proc.c中定义),
我们接下来的任务就是为它创建一个上下文, 然后切换到它来执行.
这样的执行流有一个专门的名称, 叫"内核线程"(kernel thread).
为什么不叫"内核进程"?
这个问题其实等价于"进程和线程有什么区别", 是个不错的问题. 而且这还属于考研八股的内容呢, 于是你肯定可以通过STFW找到很多五花八门的答案, 比如"线程更加轻量级", "线程没有独立的资源"等等.
如果要进一步解释"什么是轻量级", "独立的资源是什么意思", 在PA中可能比较困难. 不过在PA中也不必深究这个问题, 目前你只需要把它们都看成执行流就可以了, 更重要的是, 这两者你都将会实现, 在代码中亲自去感受它们的区别不是一个更好的选择吗? 另外, 带着这个问题去修读下学期的操作系统课也不错.
创建内核线程的上下文是通过CTE提供的kcontext()函数
(在abstract-machine/am/src/$ISA/nemu/cte.c中定义)来实现的,
其中的"k"代表内核. kcontext()的原型是
Context* kcontext(Area kstack, void (*entry)(void *), void *arg);
其中kstack是栈的范围, entry是内核线程的入口, arg则是内核线程的参数.
你需要在kstack的底部创建一个以entry为返回地址的上下文结构(目前你可以先忽略arg参数),
然后返回这一结构的指针.
在Nanos-lite中, 我们可以通过一个context_kload()函数来进行进一步的封装:
它会调用kcontext()来创建上下文, 并把返回的指针记录到PCB的cp中:
| |
+---------------+ <---- kstack.end
| |
| context |
| |
+---------------+ <--+
| | |
| | |
| | |
| | |
+---------------+ |
| cp | ---+
+---------------+ <---- kstack.start
| |
线程/进程调度
上下文的创建和切换是CTE的工作, 而具体切换到哪个上下文,
则是由操作系统来决定的, 这项任务叫做进程调度.
进程调度是由schedule()函数(在nanos-lite/src/proc.c中定义)来完成的,
它用于返回将要调度的进程上下文.
因此, 我们需要一种方式来记录当前正在运行哪一个进程,
这样我们才能在schedule()中返回另一个进程的上下文, 以实现多任务的效果.
这一工作是通过current指针(在nanos-lite/src/proc.c中定义)来实现的,
它用于指向当前运行进程的PCB.
这样, 我们就可以在schedule()中通过current来决定接下来要调度哪一个进程了.
不过在调度之前, 我们还需要把当前进程的上下文指针保存在PCB当中:
// save the context pointer
current->cp = prev;
// always select pcb[0] as the new process
current = &pcb[0];
// then return the new context
return current->cp;
目前我们让schedule()总是切换到pcb[0].
注意它的上下文是通过kcontext()创建的,
在schedule()中才决定要切换到它, 然后在CTE的__am_asm_trap()中才真正地恢复这一上下文.
机制和策略解耦
这其实体现了系统设计中的一种重要原则: 机制和策略解耦. 机制解决的是"能不能做"的问题, 而策略解决的则是"怎么做好"的问题. 显然, 策略需要机制的支撑, 机制需要策略来发挥最大的效果.
解耦的好处就很明显了: 代码重用率高, 而且容易理解. 在Project-N中, 这一解耦几乎做到了极致: 机制和策略被分离到两个子项目中. 比如, "上下文切换"这一机制是在AM的CTE中实现的, 它让系统可以做到"执行流的切换"这件事; 而具体要切换到哪一个执行流, 则是在Nanos-lite中实现的.
AM的另外一个好处是将底层硬件的行为抽象成系统级机制,
AM上的应用(包括OS)只需要调用这些系统级机制, 并实现相应的策略即可.
当然目前schedule()中的策略非常简单, 下学期的操作系统实验,
甚至是现实中更复杂的进程调度策略, 都可以在AM提供的同一个机制之上实现.
实现上下文切换
根据讲义的上述内容, 实现以下功能:
- CTE的
kcontext()函数 - Nanos-lite的
context_kload()函数(框架代码未给出该函数的原型) - Nanos-lite的
schedule()函数 - 在Nanos-lite收到
EVENT_YIELD事件后, 调用schedule()并返回新的上下文 - 修改CTE中
__am_asm_trap()的实现, 使得从__am_irq_handle()返回后, 先将栈顶指针切换到新进程的上下文结构, 然后才恢复上下文, 从而完成上下文切换的本质操作
你需要在init_proc()中单独创建一个以hello_fun为返回地址的上下文:
void init_proc() {
context_kload(&pcb[0], hello_fun, NULL);
switch_boot_pcb();
}
其中调用switch_boot_pcb()是为了初始化current指针.
如果你的实现正确, 你将会看到hello_fun()中的输出信息.
需要注意的是, 虽然hello_fun()带有一个参数arg,
但目前我们并不使用它, 所以kcontext()中的arg参数也可以先忽略,
我们接下来就会考虑它.
一些提示
schedule()函数很容易, 需要思考的是kcontext().
我们希望代码将来从__am_asm_trap()返回之后, 就会开始执行hello_fun().
换句话说, 我们需要在kcontext()中构造一个上下文, 它指示了一个状态,
从这个状态开始, 可以正确地开始执行hello_fun().
所以你需要思考的是, 为了可以正确地开始执行hello_fun(),
这个状态究竟需要满足什么样的条件?
至于"先将栈顶指针切换到新进程的上下文结构", 很自然的问题就是, 新进程的上下文结构在哪里? 怎么找到它? 又应该怎么样把栈顶指针切换过去? 如果你发现代码跑飞了, 不要忘记, 程序是个状态机.
在native上进行上下文切换
由于native的AM在创建上下文的时候默认会打开中断, 为了让Nanos-lite可以成功运行native创建的内核线程, 你还需要在Nanos-lite中识别出时钟中断事件. 我们会在PA4的最后介绍时钟中断相关的内容, 目前识别出时钟中断事件之后什么都不用做, 直接返回相应的上下文结构即可.
配合DiffTest
为了保证DiffTest的正确运行, 根据你选择的ISA, 你还需要进行一些额外的设置:
- x86: 把上下文结构中的
cs设置为8. - riscv32: 把上下文结构中的
mstatus设置为0x1800. - riscv64, 把上下文结构中的
mstatus设置为0xa00001800.
内核线程的参数
你也许会疑惑, 不就是执行hello_fun()函数吗, 为什么不能直接调用它,
搞这么复杂, 究竟有什么好处? 现在我们就来展示其中的好处.
还记得hello_fun()带了一个arg参数吗? 我们来创建两个内核线程,
给它们传递不同的参数, 然后在输出的信息中把参数也一同输出,
这样我们就能看到执行流在两个内核线程之间来回切换了!
首先需要解决的第一个问题是, 我们要如何通过kcontext()给hello_fun()传参?
于是我们需要继续思考, hello_fun()将会如何读出它的参数?
噢, 这不就是调用约定的内容吗? 你已经非常熟悉了.
我们只需要让kcontext()按照调用约定将arg放置在正确的位置,
将来hello_fun()执行的时候就可以获取正确的参数了.
mips32和riscv32的调用约定
我们没有给出mips32和riscv32的调用约定, 你需要查阅相应的ABI手册. 当然, 你也可以自己动手实践来总结传参的规则.
第二个问题是如何在两个内核线程之间来回切换.
hello_fun()中每次输出完信息都会调用yield(),
因此我们只需要对schedule()进行简单的修改即可:
current = (current == &pcb[0] ? &pcb[1] : &pcb[0]);
实现上下文切换(2)
根据讲义的上述内容, 实现以下功能:
- 修改CTE的
kcontext()函数, 使其支持参数arg的传递 - 通过
kcontext()创建第二个以hello_fun()为入口的内核线程, 并传递不同的参数 - 修改Nanos-lite的
schedule()函数, 使其轮流返回两个上下文
你可以自行约定用何种类型来解析参数arg(整数, 字符, 字符串, 指针等皆可),
然后修改hello_fun()中的输出代码, 来按照你约定的方式解析arg.
如果你的实现正确, 你将会看到hello_fun()会轮流输出不同参数的信息.
在真实的操作系统中, 内核中的很多后台任务, 守护服务和驱动程序都是以内核线程的形式存在的.
如果你执行ps aux, 你就会看到系统中有很多COMMAND中带有中括号的内核线程(例如[kthreadd]).
而创建和执行它们的原理, 也是和上面的实验内容非常相似(当然具体实现肯定会有所不同).
保持kcontext()的特性
AM在定义kcontext()的行为时, 还要求kcontext()只能在栈上放置一个上下文结构,
而不能放置更多的内容. 这样的要求有两点好处:
kcontext()对栈的写入只有一个上下文结构的内容, 而不会产生其它的副作用- OS可以预测调用
kcontext()之后的返回值, 并且利用这一确定的特性进行一些检查或者简化某些实现
我们知道x86是通过栈来传递参数的, 如果kcontext()需要支持arg的传递,
它就需要往栈上放置更多的内容, 这样就违反了上述确定性了.
但在PA中, 这并不会导致致命的问题, 因此我们并不要求你的kcontext()实现严格遵守这一确定性.
但你还是可以思考如何在遵守确定性的情况下实现参数的传递.
一个解决方案是通过引入一个辅助函数来将真正的参数传递从kcontext()推迟到内核线程的运行时刻.
具体地, 我们可以在kcontext()中先把内核线程的入口设置为辅助函数,
并把参数设置到某个可用的寄存器中. 这样以后, 内核线程就会从辅助函数开始执行,
此时让辅助函数来把之前设置的参数从寄存器中放置到栈上, 再调用真正的线程入口函数(hello_fun()).
这一方案和Linux中加载用户程序还是有一些相似之处的:
用户程序在运行的时候也并不是直接把main()函数作为入口,
而是先从CRT定义的_start()开始运行, 进行包括设置参数在内的一系列初始化操作,
最后才调用main()函数.
如果你选择的ISA是x86, 你可以尝试在CTE中实现上述辅助函数. 考虑到要直接操作寄存器和栈, 这个辅助函数还是通过汇编代码来编写比较合适. 不过由于这个辅助函数的功能比较简单, 你只需要编写几条指令就可以实现它了.
用户进程
创建用户进程上下文
创建用户进程的上下文则需要一些额外的考量.
在PA3的批处理系统中, 我们在naive_uload()中直接通过函数调用转移到用户进程的代码,
那时候使用的还是内核区的栈, 万一发生了栈溢出, 确实会损坏操作系统的数据,
不过当时也只有一个用户进程在运行, 我们也就不追究了.
但在多道程序操作系统中, 系统中运行的进程就不止一个了,
如果让用户进程继续使用内核区的栈, 万一发生了栈溢出,
就会影响到其它进程的运行, 这是我们不希望看到的.
如果内核线程发生了栈溢出, 怎么办?
如果能检测出来, 最好的方法就是触发kernel panic, 因为这时候内核的数据已经不再可信, 如果将一个被破坏的数据写回磁盘, 将会造成无法恢复的毁灭性损坏.
好消息是, 内核线程的正确性可以由内核开发人员来保证, 这至少要比保证那些来路不明的用户进程的正确性要简单多了. 而坏消息则是, 大部分的内核bug都是第三方驱动程序导致的: 栈溢出算是少见的了, 更多的是use-after-free, double-free, 还有难以捉摸的并发bug. 而面对海量的第三方驱动程序, 内核开发人员也难以逐一保证其正确性. 如果你想到一个可以提升驱动程序代码质量的方法, 那就是为计算机系统领域作出贡献了.
因此, 和内核线程不同, 用户进程的代码, 数据和堆栈都应该位于用户区,
而且需要保证用户进程能且只能访问自己的代码, 数据和堆栈.
为了区别开来, 我们把PCB中的栈称为内核栈, 位于用户区的栈称为用户栈.
于是我们需要一个有别于kcontext()的方式来创建用户进程的上下文,
为此AM额外准备了一个API ucontext()(在abstract-machine/am/src/nemu/isa/$ISA/vme.c中定义),
它的原型是
Context* ucontext(AddrSpace *as, Area kstack, void *entry);
其中, 参数as用于限制用户进程可以访问的内存, 我们在下一阶段才会使用, 目前可以忽略它;
kstack是内核栈, 用于分配上下文结构, entry则是用户进程的入口.
由于目前我们忽略了as参数, 所以ucontext()的实现和kcontext()几乎一样,
甚至比kcontext()更简单: 连参数都不需要传递.
不过你还是需要思考, 对于用户进程来说, 它需要一个什么样的状态来开始执行呢?
咦, 说好的用户栈呢? 事实上, 用户栈的分配是ISA无关的,
所以用户栈相关的部分就交给Nanos-lite来进行, ucontext()无需处理.
目前我们让Nanos-lite把heap.end作为用户进程的栈顶,
然后把这个栈顶赋给用户进程的栈指针寄存器就可以了.
哎呀, 栈指针寄存器可是ISA相关的, 在Nanos-lite里面不方便处理.
别着急, 还记得用户进程的那个_start吗? 在那里可以进行一些ISA相关的操作.
于是Nanos-lite和Navy作了一项约定: Nanos-lite把栈顶位置设置到GPRx中,
然后由Navy里面的_start来把栈顶位置真正设置到栈指针寄存器中.
Nanos-lite可以把上述工作封装到context_uload()函数中, 这样我们就可以加载用户进程了.
我们把其中一个hello_fun()内核线程替换成仙剑奇侠传:
context_uload(&pcb[1], "/bin/pal");
然后我们还需要在serial_write(), events_read()
和fb_write()的开头调用yield(), 来模拟设备访问缓慢的情况.
添加之后, 访问设备时就要进行上下文切换, 从而实现多道程序系统的功能.
实现多道程序系统
根据讲义的上述内容, 实现以下功能, 从而实现多道程序系统:
- VME的
ucontext()函数 - Nanos-lite的
context_uload()函数(框架代码未给出该函数的原型) - 在Navy的
_start中设置正确的栈指针
如果你的实现正确, 你将可以一边运行仙剑奇侠传的同时, 一边输出hello信息.
需要注意的是, 为了让AM native正确运行, 你也需要在Navy的_start中设置正确的栈指针.
思考一下, 如何验证仙剑奇侠传确实在使用用户栈而不是内核栈?
一山不能藏二虎?
尝试把hello_fun()换成Navy中的hello:
-context_kload(&pcb[0], (void *)hello_fun, NULL);
+context_uload(&pcb[0], "/bin/hello");
context_uload(&pcb[1], "/bin/pal");
你发现了什么问题? 为什么会这样? 思考一下, 答案会在下一阶段揭晓!
用户进程的参数
我们在实现内核线程的时候, 给它传递了一个arg参数.
事实上, 用户进程也可以有自己的参数, 那就是你在程序设计课上学习过的argc和argv了,
还有一个你也许不怎么熟悉的envp. envp是环境变量指针, 它指向一个字符串数组,
字符串的格式都是形如xxx=yyy, 表示有一个名为xxx的变量, 它的值为yyy.
我们在PA0中通过init.sh初始化PA项目的时候, 它会在.bashrc文件中定义一些环境变量, 比如AM_HOME.
当我们编译FCEUX的时候, make程序就会解析fceux-am/Makefile中的内容,
当遇到
include $(AM_HOME)/Makefile
的时候, 就会尝试通过getenv()这个库函数在envp指向的字符串数组里面寻找是否有形如
AM_HOME=yyy的字符串, 如果有, 就返回yyy. 如果AM_HOME指向了正确的路径,
make程序就可以找到abstract-machine项目中的Makefile文件并包含进来.
事实上, main()函数完整的原型应该是
int main(int argc, char *argv[], char *envp[]);
那么, 当我们在终端里面键入
make ARCH=x86-nemu run
的时候, ARCH=x86-nemu和run这两个参数以及环境变量都是怎么传递给make程序的main()函数的呢?
既然用户进程是操作系统来创建的, 很自然参数和环境变量的传递就需要由操作系统来负责.
最适合存放参数和环境变量的地方就是用户栈了, 因为在首次切换到用户进程的时候,
用户栈上的内容就已经可以被用户进程访问. 于是操作系统在加载用户进程的时候,
还需要负责把argc/argv/envp以及相应的字符串放在用户栈中,
并把它们的存放方式和位置作为和用户进程的约定之一,
这样用户进程在_start中就可以根据约定访问它们了.
这项约定其实属于ABI的内容, ABI手册有一节Process Initialization的内容,
里面详细约定了操作系统需要为用户进程的初始化提供哪些信息.
不过在我们的Project-N系统里面, 我们只需要一个简化版的Process Initialization就够了:
操作系统将argc/argv/envp及其相关内容放置到用户栈上, 然后将GPRx设置为argc所在的地址.
| |
+---------------+ <---- ustack.end
| Unspecified |
+---------------+
| | <----------+
| string | <--------+ |
| area | <------+ | |
| | <----+ | | |
| | <--+ | | | |
+---------------+ | | | | |
| Unspecified | | | | | |
+---------------+ | | | | |
| NULL | | | | | |
+---------------+ | | | | |
| ...... | | | | | |
+---------------+ | | | | |
| envp[1] | ---+ | | | |
+---------------+ | | | |
| envp[0] | -----+ | | |
+---------------+ | | |
| NULL | | | |
+---------------+ | | |
| argv[argc-1] | -------+ | |
+---------------+ | |
| ...... | | |
+---------------+ | |
| argv[1] | ---------+ |
+---------------+ |
| argv[0] | -----------+
+---------------+
| argc |
+---------------+ <---- cp->GPRx
| |
上图把这些参数分成两部分, 一部分是字符串区域(string area),
另一部分是argv/envp这两个字符串指针数组, 数组中的每一个元素是一个字符串指针,
而这些字符串指针都会指向字符串区域中的某个字符串.
此外, 上图中的Unspecified表示一段任意长度(也可为0)的间隔,
字符串区域中各个字符串的顺序也不作要求, 只要用户进程可以通过argv/envp访问到正确的字符串即可.
这些参数的放置格式与ABI手册中的描述非常类似, 你也可以参考ICS课本第七章的某个图.
阅读ABI手册, 理解计算机系统
事实上, ABI手册是ISA, OS, 编译器, 运行时环境, C语言和用户进程的桥梁, 非常值得大家去阅读. ICS课本上那些让你摸不着头脑的约定, 大部分也是出自ABI手册. Linux上遵守的ABI是System V ABI, 它又分为两部分, 一部分是和处理器无关的generic ABI(gABI), 例如ELF格式, 动态连接, 文件系统结构等; 另一部分是和处理器相关的processor specific ABI(psABI), 例如调用约定, 操作系统接口, 程序加载等. 你至少也应该去看看ABI手册的目录, 翻一下正文部分的图, 这样你就会对ABI手册有一个大致的了解. 如果你愿意深入推敲一下"为什么这样约定", 那就是真正的"深入理解计算机系统了".
根据这一约定, 你还需要修改Navy中_start的代码, 把argc的地址作为参数传递给call_main().
然后修改call_main()的代码, 让它解析出真正的argc/argv/envp, 并调用main():
void call_main(uintptr_t *args) {
argc = ???
argv = ???
envp = ???
environ = envp;
exit(main(argc, argv, envp));
assert(0);
}
这样以后, 用户进程就可以接收到属于它的参数了.
给用户进程传递参数
这个任务的本质是一个指针相关的编程练习,
不过你需要注意编写可移植的代码, 因为call_main()是被各种ISA所共享的.
然后修改仙剑奇侠传的少量代码, 如果它接收到一个--skip参数,
就跳过片头商标动画的播放, 否则不跳过. 实现这个功能将有利于加速仙剑奇侠传的测试.
商标动画的播放从代码逻辑上距离main()函数并不远, 于是就交给你来RTFSC吧.
不过为了给用户进程传递参数, 你还需要修改context_uload()的原型:
void context_uload(PCB *pcb, const char *filename, char *const argv[], char *const envp[]);
这样你就可以在init_proc()中直接给出用户进程的参数来测试了:
在创建仙剑奇侠传用户进程的时候给出--skip参数, 你需要观察到仙剑奇侠传确实跳过了商标动画.
目前我们的测试程序中不会用到环境变量, 所以不必传递真实的环境变量字符串.
至于实参应该写什么, 这又是一个指针相关的问题, 就交给你来解决吧.
让操作系统为每一个用户进程手动设定参数是一件不现实的事情,
因为用户进程的参数还是应该由用户来指定的.
于是最好能有一个方法能把用户指定的参数告诉操作系统,
让操作系统来把指定的参数放到新进程的用户栈里面.
这个方法当然就是系统调用SYS_execve啦, 如果你去看man, 你会发现它的原型是
int execve(const char *filename, char *const argv[], char *const envp[]);
为什么少了一个const?
在main()函数中, argv和envp的类型是char * [],
而在execve()函数中, 它们的类型则是char *const [].
从这一差异来看, main()函数中argv和envp所指向的字符串是可写的,
你知道为什么会这样吗?
为了实现带参数的SYS_execve, 我们可以在sys_execve()中直接调用context_uload().
但我们还需要考虑如下的一些细节, 为了方便描述,
我们假设用户进程A将要通过SYS_execve来执行另一个新程序B.
- 如何在A的执行流中创建用户进程B?
- 如何结束A的执行流?
为了回答第一个问题, 我们需要回顾创建用户进程B需要进行哪些操作.
首先是在PCB的内核栈中创建B的上下文结构, 这个过程是安全的, 因为当前进程的内核栈是空的.
接下来就是要在用户栈中放置用户进程B的参数.
但这会涉及到一个新的问题: 我们是否还能复用位于heap.end附近的同一个用户栈?
为了探究这个问题, 我们需要了解当Nanos-lite尝试通过SYS_execve加载B时, A的用户栈里面已经有什么内容.
我们可以从栈底(heap.end)到栈顶(栈指针sp当前的位置)列出用户栈中的内容:
- Nanos-lite之前为A传递的用户进程参数(
argc/argv/envp) - A从
_start开始进行函数调用的栈帧, 这个栈帧会一直生长, 直到调用了libos中的execve() - CTE保存的上下文结构, 这是由于A在
execve()中执行了系统调用自陷指令导致的 - Nanos-lite从
__am_irq_handle()开始进行函数调用的栈帧, 这个栈帧会一直生长, 直到调用了SYS_execve的系统调用处理函数
通过上述分析, 我们得出一个重要的结论: 在加载B时, Nanos-lite使用的是A的用户栈!
这意味着在A的执行流结束之前, A的用户栈是不能被破坏的.
因此heap.end附近的用户栈是不能被B复用的, 我们应该申请一段新的内存作为B的用户栈,
来让Nanos-lite把B的参数放置到这个新分配的用户栈里面.
为了实现这一点, 我们可以让context_uload()统一通过调用new_page()函数来获得用户栈的内存空间.
new_page()函数在nanos-lite/src/mm.c中定义, 它会通过一个pf指针来管理堆区,
用于分配一段大小为nr_page * 4KB的连续内存区域, 并返回这段区域的首地址.
我们让context_uload()通过new_page()来分配32KB的内存作为用户栈,
这对PA中的用户程序来说已经足够使用了.
此外为了简化, 我们在PA中无需实现free_page().
操作系统的内存管理
我们知道klib中的malloc()函数也可以进行堆区的管理, 使得AM应用可以方便地进行动态内存申请.
但操作系统作为一个特殊的AM应用, 很多时候对动态内存申请却有更严格的要求,
例如申请一段起始地址是4KB整数倍的内存区域, malloc()通常不能满足这样的要求.
因此操作系统一般都会自己来管理堆区, 而不会调用klib中的malloc().
在操作系统中管理堆区是MM(Memory Manager)模块的工作, 我们会在后续内容中进一步介绍它.
最后, 为了结束A的执行流, 我们可以在创建B的上下文之后,
通过switch_boot_pcb()修改当前的current指针, 然后调用yield()来强制触发进程调度.
这样以后, A的执行流就不会再被调度, 等到下一次调度的时候, 就可以恢复并执行B了.
实现带参数的execve()
根据上述讲义内容, 实现带参数的execve(). 有一些细节我们并没有完全给出,
例如调用context_uload()的pcb参数应该传入什么内容, 这个问题就交给你来思考吧!
实现后, 运行以下程序:
- 测试程序
navy-apps/tests/exec-test, 它会以参数递增的方式不断地执行自身. 不过由于我们没有实现堆区内存的回收,exec-test在运行一段时间之后,new_page()就会把0x3000000/0x83000000附近的内存分配出去, 导致用户进程的代码段被覆盖. 目前我们无法修复这一问题, 你只需要看到exec-test可以正确运行一段时间即可. - MENU开机菜单.
- 完善NTerm的內建Shell, 使得它可以解析输入的参数, 并传递给启动的程序.
例如可以在NTerm中键入
pal --skip来运行仙剑奇侠传并跳过商标动画.
运行Busybox
我们已经成功运行了NTerm, 但却没多少Shell工具可以运行. Busybox正是用来解决这个问题的, 它是一个精简版Shell工具的集合, 包含了大部分常用命令的常用功能. 噢, 你平时在Linux中使用命令行的经历, 很快就可以在你自己构建的计算机系统里面呈现了!
Navy的框架代码已经准备了Busybox的编译脚本, 首次编译Busybox时脚本会自动克隆项目, 并使用框架代码提供的配置文件. Busybox中包含很多小工具, 你可以通过
make menuconfig
来打开一个配置菜单来查看它们(但不要保存对配置的修改). 框架代码提供的配置文件默认只选中了很少的工具, 这是因为大部分工具都需要更多系统调用的支持才能运行, 因此我们无法在Nanos-lite上运行它们.
Busybox会把其中的Shell工具链接成一个ELF可执行文件, 而不是像Ubuntu/Debian等发行版中的Shell工具那样,
每个工具都是独立的ELF可执行文件. Busybox的main()函数会根据传入的参数来调用相应工具的功能:
if (strcmp(argv[1], "cat") == 0) return cat_main(argc, argv);
else if (strcmp(argv[1], "ls") == 0) return ls_main(argc, argv);
else if (strcmp(argv[1], "wc") == 0) return wc_main(argc, argv);
// ......
Busybox提供了一个简单的安装脚本, 通过创建一系列的软链接来让用户方便地使用这些小工具:
$ ls -lh navy-apps/fsimg/bin
total 1.6M
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 base64 -> busybox
-rwxr-xr-x 1 yzh yzh 161K Oct 21 12:11 bird
-rwxr-xr-x 1 yzh yzh 126K Dec 9 12:12 busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 cat -> busybox
-rwxr-xr-x 1 yzh yzh 33K Oct 20 20:43 cpp-test
-rwxr-xr-x 1 yzh yzh 29K Dec 9 12:12 dummy
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 echo -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 ed -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 false -> busybox
-rwxr-xr-x 1 yzh yzh 33K Dec 9 12:12 hello
-rwxr-xr-x 1 yzh yzh 81K Dec 9 12:12 menu
-rwxr-xr-x 1 yzh yzh 91K Dec 9 12:12 nterm
-rwxr-xr-x 1 yzh yzh 586K Dec 9 12:12 onscripter
-rwxr-xr-x 1 yzh yzh 390K Dec 9 12:12 pal
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 printenv -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 sleep -> busybox
lrwxrwxrwx 1 yzh yzh 7 Dec 9 12:12 true -> busybox
这样以后, 我们键入cat命令, 实际上是执行/bin/busybox, 来让它执行链接到Busybox的cat_main()函数.
运行Busybox
尝试通过NTerm运行Busybox中的一些简单命令, 比如cat和printenv等.
如果你不清楚这些命令的用法, 可以通过man来查阅它们.
注意不要让这些命令的输出淹没在hello_fun()打印的信息中,
为此你可能需要调整hello_fun()打印信息的频率.
有一些工具并不是放在/bin目录下, 而是放在/usr/bin目录下, 例如wc.
为了不必输入完整的路径, 我们可以把/usr/bin也加入到PATH环境变量中.
不同的路径通过:进行分隔, 具体格式可以参考在Linux上运行echo $PATH命令的结果.
这样以后, 我们就可以通过一个库函数execvp()来尝试遍历PATH中的所有路径,
直到找到一个存在的可执行文件为止, 找到之后就会调用SYS_execve.
你可以通过阅读navy-apps/libs/libc/src/posix/execvp.c来了解这一功能是如何实现的.
不过为了遍历PATH中的路径, execvp()可能会尝试执行一个不存在的用户程序, 例如/bin/wc.
因此Nanos-lite在处理SYS_execve系统调用的时候就需要检查将要执行的程序是否存在,
如果不存在, 就需要返回一个错误码.
我们可以通过fs_open()来进行检查, 如果需要打开的文件不存在,
就返回一个错误的值, 此时SYS_execve返回-2.
另一方面, libos中的execve()还需要检查系统调用的返回值:
如果系统调用的返回值小于0, 则通常表示系统调用失败, 此时需要将系统调用返回值取负,
作为失败原因设置到一个全局的外部变量errno中, 然后返回-1.
-2和errno
errno是C标准定义的, 运行时环境中的一个全局变量,
用于存放最近一次失败的系统调用或库函数调用的错误码.
你可以通过运行errno -l命令(需要通过apt-get安装moreutils包)
来查看所有的错误码及其含义, 你应该能看到错误码2是你比较熟悉的一种错误.
关于errno全局变量的更多信息, 可以参考man 3 errno.
运行Busybox(2)
实现上述内容, 让execvp()支持PATH的遍历.
然后尝试通过NTerm运行wc等位于/usr/bin目录下的命令,
例如wc /share/games/bird/atlas.txt.
你可以通过在Linux上运行相应命令来查看结果是否正确.
此外, 你可以通过阅读execvp()的代码来帮助你判断返回值的设置是否正确.
虽然目前我们只能在Nanos-lite上运行很少部分的Busybox工具, 但你基本上在自己构建的计算机系统里面呈现了与你平时使用Linux命令行工具非常相似的一幕. 我们把这件事放到Project-N的系统栈里面, 就是为了能够让你明白, 你平时键入命令的时候计算机系统的各个抽象层都做了些什么:
- 终端如何读取用户的按键?
- Shell如何进行命令的解析?
- 库函数如何根据命令解析出的字符串搜索到可执行文件?
- 操作系统如何加载执行一个可执行文件?
- ......
虽然Project-N和真实的Linux系统还有很大的差异, 但独立完成PA已经可以很大程度上帮助你消除对"程序如何在计算机上运行"的神秘感.
温馨提示
PA4阶段1到此结束.