超越容量的界限
现代操作系统不使用分段还是有一定的道理的. 有研究表明, Google数据中心中的1000台服务器在7分钟内就运行了上千个不同的程序, 其中有的是巨大无比的家伙(Google内部开发程序的时候为了避免不同计算机上的动态库不兼容的问题, 用到的所有库都以静态链接的方式成为程序的一部分, 光是程序的代码段就有几百MB甚至上GB的大小, 感兴趣的同学可以阅读这篇文章), 有的只是一些很小的测试程序. 让这些特征各异的程序都占用连续的存储空间并不见得有什么好处: 一方面, 那些巨大无比的家伙们在一次运行当中只会触碰到很小部分的代码, 其实没有必要分配那么多内存把它们全部加载进来; 另一方面, 小程序运行结束之后, 它占用的存储空间就算被释放了, 也很容易成为"碎片空洞" - 只有比它更小的程序才能把碎片空洞用起来. 分段机制的简单朴素, 在现实中也许要付出巨大的代价.
事实上, 我们需要一种按需分配的虚存管理机制. 之所以分段机制不好实现按需分配, 就是因为段的粒度太大了, 为了实现这一目标, 我们需要反其道而行之: 把连续的存储空间分割成小片段, 以这些小片段为单位进行组织, 分配和管理. 这正是分页机制的核心思想.
分页
在分页机制中, 这些小片段称为页面, 在虚拟地址空间和物理地址空间中也分别称为虚拟页和物理页. 分页机制做的事情, 就是把一个个的虚拟页分别映射到相应的物理页上. 显然, 这一映射关系并不像分段机制中只需要一个段基址寄存器就可以描述的那么简单. 分页机制引入了一个叫"页表"的结构, 页表中的每一个表项记录了一个虚拟页到物理页的映射关系, 来把不必连续的物理页面重新组织成连续的虚拟地址空间. 因此, 为了让分页机制支撑多任务操作系统的运行, 操作系统首先需要以物理页为单位对内存进行管理. 每当加载程序的时候, 就给程序分配相应的物理页(注意这些物理页之间不必连续), 并为程序准备一个新的页表, 在页表中填写程序用到的虚拟页到这些物理页的映射关系. 等到程序运行的时候, 操作系统就把之前为这个程序填写好的页表设置到MMU中, MMU就会根据页表的内容进行地址转换, 把程序的虚拟地址空间映射到操作系统所希望的物理地址空间上.
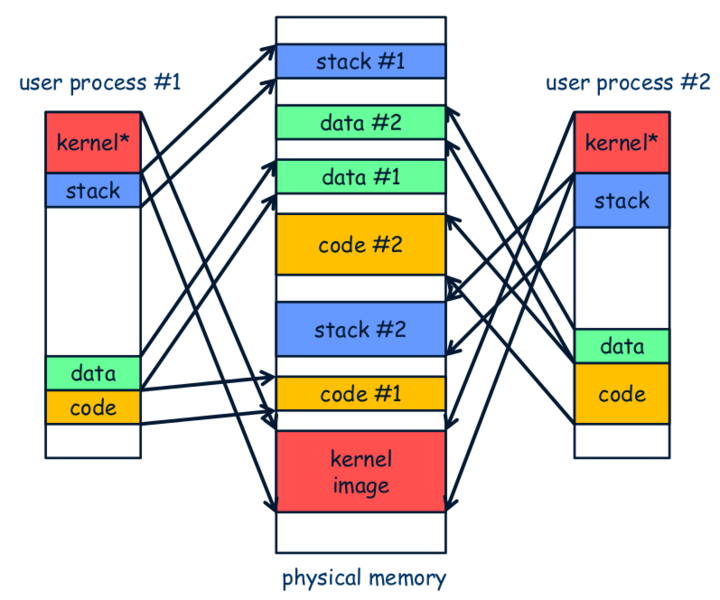
虚存管理中PIC的好处
我们之前提到, PIC的其中一个好处是可以将代码加载到任意内存位置执行. 如果配合虚存管理, PIC还有什么新的好处呢? (Hint: 动态库已经在享受这些好处了)
i386是x86史上首次引进分页机制的处理器, 它把物理内存划分成以4KB为单位的页面, 同时也采用了二级页表的结构. 为了方便叙述, i386给第一级页表取了个新名字叫"页目录". 虽然听上去很厉害, 但其实原理都是一样的. 每一张页目录和页表都有1024个表项, 每个表项的大小都是4字节, 除了包含页表(或者物理页)的基地址, 还包含一些标志位信息. 因此, 一张页目录或页表的大小是4KB, 要放在寄存器中是不可能的, 因此它们要放在内存中. 为了找到页目录, i386提供了一个CR3(control register 3)寄存器, 专门用于存放页目录的基地址. 这样, 页级地址转换就从CR3开始一步一步地进行, 最终将虚拟地址转换成真正的物理地址, 这个过程称为一次page table walk.
PAGE FRAME
+-----------+-----------+----------+ +---------------+
| DIR | PAGE | OFFSET | | |
+-----+-----+-----+-----+-----+----+ | |
| | | | |
+-------------+ | +------------->| PHYSICAL |
| | | ADDRESS |
| PAGE DIRECTORY | PAGE TABLE | |
| +---------------+ | +---------------+ | |
| | | | | | +---------------+
| | | | |---------------| ^
| | | +-->| PG TBL ENTRY |--------------+
| |---------------| |---------------|
+->| DIR ENTRY |--+ | |
|---------------| | | |
| | | | |
+---------------+ | +---------------+
^ | ^
+-------+ | +---------------+
| CR3 |--------+
+-------+
我们不打算给出分页过程的详细解释, 请你结合i386手册的内容和课堂上的知识, 尝试理解i386分页机制, 这也是作为分页机制的一个练习. i386手册中包含你想知道的所有信息, 包括这里没有提到的表项结构, 地址如何划分等.
理解分页细节
- i386不是一个32位的处理器吗, 为什么表项中的基地址信息只有20位, 而不是32位?
- 手册上提到表项(包括CR3)中的基地址都是物理地址, 物理地址是必须的吗? 能否使用虚拟地址?
- 为什么不采用一级页表? 或者说采用一级页表会有什么缺点?
页级转换的过程并不总是成功的, 因为i386也提供了页级保护机制, 实现保护功能就要靠表项中的标志位了. 我们对一些标志位作简单的解释:
- present位表示物理页是否可用, 不可用的时候又分两种情况:
- 物理页面由于交换技术被交换到磁盘中了, 这就是你在课堂上最熟悉的Page fault的情况之一了, 这时候可以通知操作系统内核将目标页面换回来, 这样就能继续执行了
- 进程试图访问一个未映射的线性地址, 并没有实际的物理页与之相对应, 因此这就是一个非法操作咯
- R/W位表示物理页是否可写, 如果对一个只读页面进行写操作, 就会被判定为非法操作
- U/S位表示访问物理页所需要的权限, 如果一个ring 3的进程尝试访问一个ring 0的页面, 当然也会被判定为非法操作
理解分页机制
上文只介绍了i386的分页机制, 事实上, 其它ISA的分页机制也是大同小异, 理解了i386分页机制之后, mips32和riscv32的分页机制也就不难理解了.
当然, 具体细节还是得RTFM.
riscv64需要实现三级页表
riscv32的Sv32机制只能对32位的虚拟地址进行地址转换, 但riscv64的虚拟地址最长是64位, 因此需要有另外的机制来支持更长的虚拟地址的地址转换. 在PA中, 如果你选择了riscv64, 那只需要实现Sv39三级页表的分页机制即可, 而且PA只会使用4KB小页面, 不会使用2MB的大页面, 因此你无需实现Sv39的大页面功能. 具体细节请RTFM.
空指针真的是"空"的吗?
程序设计课上老师告诉你, 当一个指针变量的值等于NULL时, 代表空, 不指向任何东西. 仔细想想, 真的是这样吗? 当程序对空指针解引用的时候, 计算机内部具体都做了些什么? 你对空指针的本质有什么新的认识?
和分段机制相比, 分页机制更灵活, 甚至可以使用超越物理地址上限的虚拟地址. 现在我们从数学的角度来理解这两点. 撇去存储保护机制不谈, 我们可以把这分段和分页的过程分别抽象成两个数学函数:
y = seg(x) = seg.base + x
y = page(x)
可以看到, seg()函数只不过是做加法.
如果仅仅使用分段机制, 我们还要求段级地址转换的结果不能超过物理地址上限:
y = seg(x) = seg.base + x < PMEM_MAX
=> x < PMEM_MAX - seg.base
=> x <= PMEM_MAX
我们可以得出这样的结论: 仅仅使用分段机制, 虚拟地址是无法超过物理地址上限的.
而分页机制就不一样了, 我们无法给出page()具体的解析式,
是因为填写页目录和页表实际上就是在用枚举自变量的方式定义page()函数,
这就是分页机制比分段机制灵活的根本原因.
虽然"页级地址转换结果不能超过物理地址上限"的约束仍然存在,
但我们只要保证每一个函数值都不超过物理地址上限即可,
并没有对自变量的取值作明显的限制, 当然自变量本身也就可以比函数值还大.
这就已经把分页的"灵活"和"允许使用超过物理地址上限"这两点特性都呈现出来了.
i386采用段页式存储管理机制. 不过仔细想想, 这只不过是把分段和分页结合起来罢了, 用数学函数来理解, 也只不过是个复合函数:
paddr = page(seg(vaddr))
而"虚拟地址空间"和"物理地址空间"这两个在操作系统中无比重要的概念, 也只不过是这个复合函数的定义域和值域而已.
最后, 支持分页机制的处理器能识别什么是页表吗? 我们以一个页面大小为1KB的一级页表的地址转换例子来认识这个问题:
pa = (pg_table[va >> 10] & ~0x3ff) | (va & 0x3ff);
可以看到, 处理器并没有表的概念: 地址转换的过程只不过是一些访存和位操作而已. 这再次向我们展示了计算机的本质: 一堆美妙的, 蕴含着深刻数学智慧和工程原理的... 门电路! 然而这些小小的门电路操作却成为了今天多任务操作系统的根基, 支撑着千千万万程序的运行, 归根到底还是离不开计算机系统抽象的核心思想.
状态机视角下的虚存管理机制
从状态机视角来看, 虚存管理机制是什么呢?
为了描述虚存管理机制在状态机视角的行为, 我们需要对状态机S = <R, M>的访存行为进行扩展.
具体地, 我们需要增加一个函数fvm: M -> M, 它就是我们上文讨论的地址转换的映射,
然后把状态机中所有对M的访问M[addr]替换成M[fvm(addr)], 就是虚存管理机制的行为.
例如指令mov $1, addr, 在虚存机制关闭时, 它的行为是TRM定义的:
M[addr] <- 1
而在虚存机制打开时, 它的行为则是:
M[fvm(addr)] <- 1
我们刚才已经讨论过, 地址转换的过程可以通过访存和位操作来实现,
这说明fvm()函数的行为也是可以通过状态机视角来描述的.
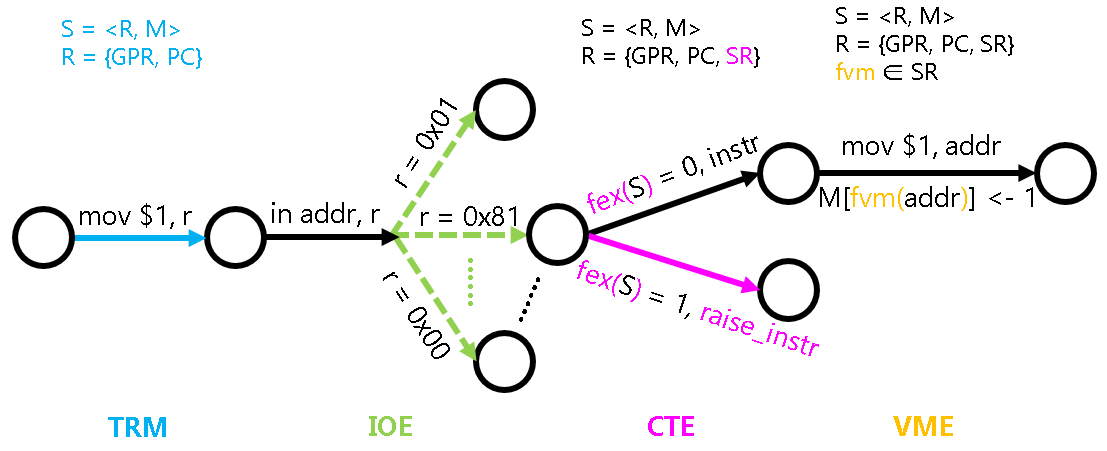
比较特殊的是fvm()这个函数. 回顾PA3介绍的状态机模型中引入的fex()函数,
它实际上并不属于状态机的一部分, 因为抛出异常的判断方式是和状态机的具体状态无关的.
而fvm()函数则有所不同, 它可以看做是是状态机的一部分,
这是因为fvm()函数是可以通过程序进行修改的: 操作系统可以决定如何建立虚拟地址和物理地址之间的映射.
具体地, fvm()函数可以认为是系统寄存器SR的一部分, 操作系统通过修改SR来对虚存进行管理.
TLB - 地址转换的加速
细心的你会发现, 在不改变页目录基地址, 页目录和页表的情况下, 如果连续访问同一个虚拟页的内容, 页级地址转换的结果都是一样的. 事实上, 这种情况太常见了, 例如程序执行的时候需要取指令, 而指令的执行一般都遵循局部性原理, 大多数情况下都在同一个虚拟页中执行. 但进行page table walk是要访问内存的, 如果有方法可以避免这些没有必要的page table walk, 就可以提高处理器的性能了.
一个很自然的想法就是将页级地址转换的结果存起来, 在进行下一次的页级地址转换之前, 看看这个虚拟页是不是已经转换过了, 如果是, 就直接取出之前的结果, 这样就可以节省不必要的page table walk了. 这不正好是cache的思想吗? 这样一个特殊的cache, 叫TLB. 我们可以从CPU cache的知识来理解TLB的组织:
- TLB的基本单元是项, 一项存放了一次页级地址转换的结果 (其实就是一个页表项, 包括物理页号和一些和物理页相关的标志位), 功能上相当于一个cache block.
- TLB项的tag由虚拟页号来充当, 表示这一项对应于哪一个虚拟页号.
- TLB的项数一般不多, 为了提高命中率, TLB一般采用全相联或者组相联的组织方式.
- 由于页目录和页表一旦建立之后, 一般不会随意修改其中的表项, 因此TLB不存在写策略和写分配方式的问题.
实践表明, 大小64项的TLB, 命中率可以高达90%, 有了TLB之后, 果然大大节省了不必要的page table walk.
听上去真不错! 不过在现代的多任务操作系统中, 如果仅仅简单按照上述方式来使用TLB, 却会导致致命的后果. 我们知道, 操作系统会为每个进程分配不同的页目录和页表, 虽然两个进程可能都会从0x8048000开始执行, 但分页机制会把它们映射到不同的物理页, 从而做到存储空间的隔离. 当然, 操作系统进行进程切换的时候也需要更新CR3的内容, 使得CR3寄存器指向新进程的页目录, 这样才能保证分页机制将虚拟地址映射到新进程的物理存储空间.
现在问题来了, 假设有两个进程, 对于同一个虚拟地址0x8048000, 操作系统已经设置好正确的页目录和页表, 让1号进程映射到物理地址0x1234000, 2号进程映射到物理地址0x5678000, 同时假设TLB一开始所有项都被置为无效. 这时1号进程先运行, 访问虚拟地址0x8048000, 查看TLB发现未命中, 于是进行page table walk, 根据1号进程的页目录和页表进行页级地址转换, 得到物理地址0x1234000, 并填充TLB. 假设此时发生了进程切换, 轮到2号进程来执行, 它也要访问虚拟地址0x8048000, 查看TLB, 发现命中, 于是不进行page table walk, 而是直接使用TLB中的物理页号, 得到物理地址0x1234000. 2号进程竟然访问了1号进程的存储空间, 但2号进程和操作系统对此都毫不知情!
出现这个致命错误的原因是, TLB没有维护好进程和虚拟地址映射关系的一致性:
TLB只知道有一个从虚拟地址0x8048000到物理地址0x1234000的映射关系,
但它并不知道这个映射关系是属于哪一个进程的.
找到问题的原因之后, 解决它也就很容易了, 只要在TLB项中增加一个域ASID(address space ID),
用于指示映射关系所属的进程即可, mips32就是这样做的.
x86的做法则比较"野蛮", 在每次更新CR3时强制冲刷TLB的内容,
由于进程切换必定伴随着CR3的更新, 因此一个进程运行的时候, TLB中不会存在其它进程的映射关系.
当然, 为了防止冲刷过猛, 页表项中有一个Global位, 那些Global位为1的映射关系则不会被冲刷,
比如可以把内核中do_syscall()所在的页面的Global位设置为1,
这样系统调用的处理过程就不会出现TLB miss了.
软件管理的TLB
对于x86和riscv32来说, TLB一般都是由硬件来负责管理的: 当TLB miss时, 硬件逻辑会自动进行page table walk, 并将地址转换结果填充到TLB中, 软件不知道也无需知道这一过程的细节. 对PA来说, 这是一个好消息: 既然对软件透明, 那么就可以简化了. 因此如果你选择了x86或者riscv32, 你不必在NEMU中实现TLB.
但mips32就不一样了, 为了降低硬件设计的复杂度, mips32规定, page table walk和TLB填充都由软件来负责. 很自然地, 在mips32中, TLB miss被设计成一种异常: 当TLB miss时, CPU将会抛出异常, 由软件来进行page table walk和TLB填充.
于是mips32需要把TLB的状态暴露给软件, 让软件可以来对TLB进行管理. 为了实现这一点, mips32至少需要添加以下内容:
- CP0寄存器, 包括entryhi, entrylo0, entrylo1, index这四个寄存器. 其中entryhi寄存器存放虚拟页号相关的信息, entrylo0寄存器和entrylo1寄存器存放物理页号相关的信息.
- CP0指令
- tlbp, 用于寻找与entryhi寄存器中匹配的TLB项, 若找到, 则将index寄存器设置为该TLB项的序号
- tlbwi, 用于将entryhi, entrylo0和entrylo1这三个寄存器的内容写入到index序号所指示的TLB项中
- tlbwr, 用于将entryhi, entrylo0和entrylo1这三个寄存器的内容写入到随机一个TLB项中
- 让mtc0和mfc0支持上述四个CP0寄存器的访问
mips32的TLB管理是否更简单?
有一种观点认为, mips32的分页机制更简单. 你认同吗? 尝试分别在现在, 以及完成这部分内容之后回答这个问题.
TLB管理是一个考量软硬件tradeoff的典型例子, mips32把这件事交给软件来做, 毫无疑问会引入额外的性能开销. 在一些性能不太重要的嵌入式场景中, 这并不会有什么大问题; 但如果是在一些面向高性能的场景中, 这种表面上简单的机制就成为了性能瓶颈的来源: 例如在数据中心场景中, 程序需要访问的数据非常多, 局部性也很差, TLB miss是非常常见的现象, 这种情况下, 软件管理TLB的性能开销就会被进一步放大.
在mips32中, 为了进一步降低page table walk带来的性能开销, 一个TLB表项其实管理的是连续两个虚拟页面的映射关系, 于是物理页号相关的寄存器有entrylo0和entrylo1两个, 分别用于表示这两个虚拟页面对应的物理页号. 具体地, 假设虚拟地址和物理地址的长度都是32位, 并采用4KB页面大小, 那么entryhi寄存器中的虚拟页号则是19位, entrylo0和entrylo1寄存器中的物理页号为20位. 这样的好处是, 在一次page table walk中可以同时填充两个虚拟页面的地址转换结果, 期望通过程序的局部性获得一些性能收益. 不过在数据中心场景面前, 这都是杯水车薪了.
将虚存管理抽象成VME
虚存管理的具体实现自然是架构相关的, 比如在x86中用于存放页目录基地址的CR3, 在riscv32上并不叫这个名字, 访问这个寄存器的指令自然也各不相同. 再者, 不同架构中的页面大小可能会有差异, 页表项的结构也不尽相同, 更不用说有的架构还可能有多于两级的页表结构了. 于是, 我们可以将虚存管理的功能划入到AM的一类新的API中, 名字叫VME(Virtual Memory Extension).
老规矩, 我们来考虑如何将虚存管理的功能抽象成统一的API. 换句话说, 虚存机制的本质究竟是什么呢? 我们在上文已经讨论过这个问题了: 虚存机制, 说白了就是个映射(或函数). 也就是说, 本质上虚存管理要做的事情, 就是在维护这个映射. 但这个映射应该是每个进程都各自维护一份, 因此我们需要如下的两个API:
// 创建一个默认的地址空间
void protect(AddrSpace *as);
// 销毁指定的地址空间
void unprotect(AddrSpace *as);
其中AddrSpace是一个结构体类型, 定义了地址空间描述符的结构(在abstract-machine/am/include/am.h中定义):
typedef struct AddrSpace {
int pgsize;
Area area;
void *ptr;
} AddrSpace;
其中pgsize用于指示页面的大小, area表示虚拟地址空间中用户态的范围,
ptr是一个ISA相关的地址空间描述符指针, 用于指示具体的映射.
有了地址空间, 我们还需要有相应的API来维护它们. 于是很自然就有了如下的API:
void map(AddrSpace *as, void *va, void *pa, int prot);
它用于将地址空间as中虚拟地址va所在的虚拟页,
以prot的权限映射到pa所在的物理页.
当prot中的present位为0时, 表示让va的映射无效.
由于我们不打算实现保护机制, 因此权限prot暂不使用.
VME的主要功能已经通过上述三个API抽象出来了. 最后还有另外两个统一的API:
bool vme_init(void *(*pgalloc_f)(int), void (*pgfree_f)(void *))用于进行VME相关的初始化操作. 其中它还接受两个来自操作系统的页面分配回调函数的指针, 让AM在必要的时候通过这两个回调函数来申请/释放一页物理页.Context* ucontext(AddrSpace *as, Area kstack, void *entry)用于创建用户进程上下文. 我们之前已经介绍过这个API, 但加入虚存管理之后, 我们需要对这个API的实现进行一些改动, 具体改动会在下文介绍.
下面我们来介绍Nanos-lite如何使用VME提供的机制.
在分页机制上运行Nanos-lite
由于页表位于内存中, 但计算机启动的时候, 内存中并没有有效的数据,
因此我们不可能让计算机启动的时候就开启分页机制.
操作系统为了启动分页机制, 首先需要准备一些内核页表.
框架代码已经为我们实现好这一功能了(见abstract-machine/am/src/$ISA/nemu/vme.c的vme_init()函数).
只需要在nanos-lite/include/common.h中定义宏HAS_VME,
Nanos-lite在初始化的时候首先就会调用init_mm()函数(在nanos-lite/src/mm.c中定义)来初始化MM.
这里的MM是指存储管理器(Memory Manager)模块, 它专门负责分页相关的存储管理.
目前初始化MM的工作有两项, 第一项工作是将TRM提供的堆区起始地址作为空闲物理页的首地址,
这样以后, 将来就可以通过new_page()函数来分配空闲的物理页了.
为了简化实现, MM可以采用顺序的方式对物理页进行分配, 而且分配后无需回收.
第二项工作是调用AM的vme_init()函数.
以riscv32为例, vme_init()将设置页面分配和回收的回调函数,
然后调用map()来填写内核虚拟地址空间(kas)的页目录和页表,
最后设置一个叫satp(Supervisor Address Translation and Protection)的CSR寄存器来开启分页机制.
这样以后, Nanos-lite就运行在分页机制之上了.
map()是VME中的核心API, 它需要在虚拟地址空间as的页目录和页表中填写正确的内容,
使得将来在分页模式下访问一个虚拟页(参数va)时, 硬件进行page table walk后得到的物理页,
正是之前在调用map()时给出的目标物理页(参数pa).
这再次体现了分页是一个软硬协同才能工作的机制: 如果map()没有正确地填写这些内容,
将来硬件进行page table walk的时候就无法取得正确的物理页.
对于x86和riscv32, vme_init()会通过map()来填写内核虚拟地址空间的映射.
这些映射十分特殊, 它们的va和pa是相同的, 我们将它们称为"恒等映射"(identical mapping).
在硬件开启分页机制之后, CPU访问的物理地址就跟分页机制关闭时相同,
从而在无需修改其它代码的情况下, 达到"Nanos-lite看起来像是直接运行在物理内存上"的效果.
建立这样一个映射也有利于Nanos-lite进行内存管理:
即使在分页模式下, Nanos-lite可以把内存的物理地址直接当做虚拟地址来访问,
访问的结果正好是相应的物理地址.
为了让map()填写的映射生效, 我们还需要在NEMU中实现分页机制.
具体地, 我们需要实现以下两点:
- 如何判断CPU当前是否处于分页模式?
- 分页地址转换的具体过程应该如何实现?
但这两点都是ISA相关的, 于是NEMU将它们抽象成相应的API:
// 检查当前系统状态下对内存区间为[vaddr, vaddr + len), 类型为type的访问是否需要经过地址转换.
int isa_mmu_check(vaddr_t vaddr, int len, int type);
// 对内存区间为[vaddr, vaddr + len), 类型为type的内存访问进行地址转换
paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type);
为了使用这些API, 你需要对NEMU中虚拟地址访问的函数进行一些修改.
具体地, 首先需要通过isa_mmu_check()来根据当前的系统状态判断一次虚拟地址的访问应该如何进行:
- 如果
isa_mmu_check()返回MMU_DIRECT, 表示可以直接把该地址作为物理地址来访问, 此时直接调用paddr_read()或paddr_write()即可 - 如果
isa_mmu_check()返回MMU_TRANSLATE, 表示该访问需要通过MMU进行地址转换, 此时需要先调用isa_mmu_translate()进行地址转换, 然后再通过地址转换后的物理地址来调用paddr_read()或paddr_write() - 根据API的定义,
isa_mmu_check()还可以返回MMU_FAIL, 表示访问失败, 需要抛出异常, 不过这种情况在PA中不会出现
如果你选择的是x86, 你需要添加CR3寄存器和CR0寄存器, 以及相应的操作它们的指令. 对于CR0寄存器, 我们只需要实现PG位即可. 如果发现CR0的PG位为1, 则说明CPU处于分页模式, 从此所有虚拟地址的访问都需要经过分页地址转换.
riscv32的Sv32分页机制和x86非常类似, 只不过寄存器的名字和页表项结构有所不同: 在riscv32中, 页目录基地址和分页使能位都是位于satp寄存器中. 至于页表项结构的差异, 这里就不详细说明了, 还是RTFM吧.
mips32的情况就大不一样了. mips32简单地规定了虚拟地址空间的划分, 在PA中我们只会用到以下三段地址空间, mips32还规定了其余空间的性质, 具体可查阅手册:
[0x80000000, 0xa0000000)属于内核空间, 不进行地址转换[0xa0000000, 0xb0000000)属于I/O空间, 不进行地址转换[0x00000000, 0x80000000)属于用户空间, 需要进行地址转换
既然mips32的内核空间不需要进行地址转换, 那么就不需要维护所谓的内核映射了;
此外, mips32是以地址空间来决定是否需要进行地址转换,
那么也就不存在"分页机制是否开启"的状态了, 所以mips32中并没有类似CR0.PG这样的状态位.
所以mips32-nemu的vme_init()非常简单, 只需要注册页面管理的回调函数即可.
你需要理解分页地址转换的过程,
然后实现isa_mmu_check()(在nemu/src/isa/$ISA/include/isa-def.h中定义)
和isa_mmu_translate()(在nemu/src/isa/$ISA/system/mmu.c中定义),
你可以查阅NEMU的ISA相关API说明文档来了解它们的行为.
另外由于我们不打算实现保护机制, 在isa_mmu_translate()的实现中,
你务必使用assertion检查页目录项和页表项的present/valid位,
如果发现了一个无效的表项, 及时终止NEMU的运行, 否则调试将会非常困难.
这通常是由于你的实现错误引起的, 请检查实现的正确性.
最后提醒一下x86页级地址转换时出现的一种特殊情况.
由于x86并没有严格要求数据对齐, 因此可能会出现数据跨越虚拟页边界的情况,
例如一条很长的指令的首字节在一个虚拟页的最后, 剩下的字节在另一个虚拟页的开头.
如果这两个虚拟页被映射到两个不连续的物理页, 就需要进行两次页级地址转换,
分别读出这两个物理页中需要的字节, 然后拼接起来组成一个完成的数据返回.
不过根据KISS法则, 你现在可以暂时不实现这种特殊情况的处理,
在判断出数据跨越虚拟页边界的情况之后, 先使用assert(0)终止NEMU,
等到真的出现这种情况的时候再进行处理.
而mips32和riscv32作为RISC架构, 指令和数据都严格按照4字节对齐, 因此不会发生这样的情况,
否则CPU将会抛出异常, 可见软件灵活性和硬件复杂度是计算机系统中又一对tradeoff.
在分页机制上运行Nanos-lite
实现以下内容:
- Nanos-lite的
pg_alloc().pg_alloc()的参数是分配空间的字节数, 但我们保证AM通过回调函数调用pg_alloc()时申请的空间总是页面大小的整数倍, 因此可以通过调用new_page()来实现pg_alloc(). 此外pg_alloc()还需要对分配的页面清零. - VME的
map(). 你可以通过as->ptr获取页目录的基地址. 若需要申请新的页表, 可以通过回调函数pgalloc_usr()向Nanos-lite获取一页空闲的物理页. - 在NEMU中实现分页机制.
由于此时Nanos-lite运行在内核的虚拟地址空间中, 而这些映射又是恒等映射,
因此NEMU的地址转换结果pa必定与va相同.
你可以把这一条件作为assertion加入到NEMU的代码中, 从而帮助你捕捉实现上的bug.
如果你的实现正确, 你会看到仙剑奇侠传也可以成功运行. 如果你对分页机制的细节有疑问, 请RTFM.
对于x86和riscv32, 你无需实现TLB.
对于mips32, 此时并不能检查你的实现是否正确, 这是因为在mips32中, 程序需要访问用户空间才会触发地址转换的过程. 因此如果你选择了mips32, 你需要完成下文的内容才能测试你的实现.
让DiffTest支持分页机制
为了让DiffTest机制正确工作, 你需要
- 对于x86:
- 在
restart()函数中我们需要对CR0寄存器初始化为0x60000011, 但我们不必关心其含义. - 实现分页机制中accessed位和dirty位的功能
- 在
- 处理
attach命令时, 需要将分页机制相关的寄存器同步到REF中 - 对快照功能进行更新
这毕竟是个选做题而已, 实现细节就不提示了, 遇到困难就自己思考一下解决方案吧.
但对于mips32来说, 引入的TLB也属于机器状态, 因此要完美地进行DiffTest, 则需要考虑如何将TLB同步到REF中. 这确实不是一件轻松的事情, 你可以思考一下如何解决, 不过放弃进行DiffTest也不失为一种解决方案.
RISC-V的分页机制
如果你仔细RTFM, 你会发现标准RISC-V的分页机制需要在S模式及U模式下才能开启, 而在M模式下的访存并不会进行MMU的地址转换. 但我们在NEMU中进行了简化, 允许M模式的访存也进行地址转换, 这样可以避免引入S模式相关的细节, 让大家把注意力集中在分页机制本身.
在分页机制上运行用户进程
成功实现分页机制之后, 你会发现仙剑奇侠传也同样成功运行了.
但仔细想想就会发现这其实不太对劲:
我们在vme_init()中创建了内核的虚拟地址空间, 之后就再也没有切换过这一虚拟地址空间.
也就是说, 我们让仙剑奇侠传也运行在内核的虚拟地址空间之上!
这太不合理了, 毕竟用户进程还是应该有自己的一套虚拟地址空间.
更可况, Navy-apps之前让用户程序链接到0x3000000/0x83000000的位置,
是因为之前Nanos-lite并没有对空闲的物理内存进行管理;
现在引入了分页机制, 由MM来负责所有物理页的分配.
这意味着, 如果将来MM把0x3000000/0x83000000所在的物理页分配出去,
仙剑奇侠传的内容将会被覆盖(你之前在运行exec-test的时候已经遇到过这个问题了)!
因此, 目前仙剑奇侠传看似运行成功, 其实里面暗藏杀机.
正确的做法是, 我们应该让用户进程运行在操作系统为其分配的虚拟地址空间之上.
为此, 我们需要对工程作一些变动.
首先, 编译Navy应用程序的时候需要为make添加VME=1的参数,
这样就可以将应用程序的链接地址改为0x40000000,
这是为了避免用户进程的虚拟地址空间与内核相互重叠, 从而产生非预期的错误.
这时, "虚拟地址作为物理地址的抽象"这一好处已经体现出来了:
原则上用户进程可以运行在任意的虚拟地址, 不受物理内存容量的限制.
我们让用户进程的代码从0x40000000附近开始,
这个地址已经不在物理内存的地址空间中(NEMU提供的物理内存是128MB),
但分页机制保证了进程能够正确运行.
这样, 链接器和程序都不需要关心程序运行时刻具体使用哪一段物理地址,
它们只要使用虚拟地址就可以了, 而虚拟地址和物理地址之间的映射则全部交给操作系统的MM来管理.
此外, 我们还需要对创建用户进程的过程进行较多的改动.
我们首先需要在加载用户进程之前为其创建地址空间.
由于地址空间是进程相关的, 我们将AddrSpace结构体作为PCB的一部分.
这样以后, 我们只需要在context_uload()的开头调用protect(), 就可以实现地址空间的创建.
目前这个地址空间除了内核映射之外就没有其它内容了,
具体可以参考abstract-machine/am/src/$ISA/nemu/vme.c.
不过, 此时loader()不能直接把用户进程加载到内存位置0x40000000附近了,
因为这个地址并不在内核的虚拟地址空间中, 内核不能直接访问它.
loader()要做的事情是, 获取程序的大小之后, 以页为单位进行加载:
- 申请一页空闲的物理页
- 通过
map()把这一物理页映射到用户进程的虚拟地址空间中. 由于AM native实现了权限检查, 为了让程序可以在AM native上正确运行, 你调用map()的时候需要将prot设置成可读可写可执行 - 从文件中读入一页的内容到这一物理页中
这一切都是为了让用户进程在将来可以正确地运行: 用户进程在将来使用虚拟地址访问内存, 在loader为用户进程维护的映射下, 虚拟地址被转换成物理地址, 通过这一物理地址访问到的物理内存, 恰好就是用户进程想要访问的数据.
另一个需要考虑的问题是用户栈, 和loader()类似,
我们需要把new_page()申请得到的物理页通过map()映射到用户进程的虚拟地址空间中.
我们把用户栈的虚拟地址安排在用户进程虚拟地址空间的末尾,
你可以通过as.area.end来得到末尾的位置,
然后把用户栈的物理页映射到[as.area.end - 32KB, as.area.end)这段虚拟地址空间.
最后, 为了让这一地址空间生效, 我们还需要将它落实到MMU中.
具体地, 我们希望在CTE恢复进程上下文的时候来切换地址空间.
为此, 我们需要将进程的地址空间描述符指针as->ptr加入到上下文中,
框架代码已经实现了这一功能(见abstract-machine/am/include/arch/$ISA-nemu.h),
在x86中这一成员为cr3, 而在mips32/riscv32中则为pdir. 你还需要
- 修改
ucontext()的实现, 在创建的用户进程上下文中设置地址空间描述符指针 - 在
__am_irq_handle()的开头调用__am_get_cur_as()(在abstract-machine/am/src/$ISA/nemu/vme.c中定义), 来将当前的地址空间描述符指针保存到上下文中 - 在
__am_irq_handle()返回前调用__am_switch()(在abstract-machine/am/src/$ISA/nemu/vme.c中定义)来切换地址空间, 将被调度进程的地址空间落实到MMU中
为mips32实现真正的分页机制
如果你选择的是mips32, 现在你需要实现真正的分页机制了; 如果不是, 你可以忽略这道题.
当CPU尝试进行地址转换时, 若TLB发生miss,
硬件会将当前的虚拟页号设置到entryhi中, 然后抛出TLB refill异常.
这个异常会被CTE捕获, 然后调用__am_tlb_refill()函数:
- 读出当前进程的页目录基地址(思考一下, 该如何获得?)
- 从entryhi中读出虚拟页号
- 根据虚拟页号进行page table walk
- 将两个连续的虚拟页对应的物理页号设置到entrylo0和entrylo1中
- 执行tlb管理的相关指令更新TLB表项
从TLB refill异常返回后, CPU会再次执行相同的指令, 这次的地址转换应该可以成功进行.
为了让软件来进行page table walk, 你需要实现__am_tlb_refill()
(在abstract-machine/am/src/mips32/nemu/vme.c中定义).
根据上文内容, 我们还需要维护TLB表项和进程的关系, 这应该是通过ASID来完成的.
不过我们在这里可以进行简化, 参考x86, 我们也在切换地址空间的时候, 通过清空整个TLB来解决问题.
为此你还需要实现__am_tlb_clear()(在abstract-machine/am/src/mips32/nemu/vme.c中定义).
在分页机制上运行用户进程
根据上述的讲义内容, 对创建用户进程的过程进行相应改动, 让用户进程在分页机制上成功运行. 如果你选择了mips32或riscv32, 请注意地址空间描述符在上下文结构体中的位置, 如果你不确定这一位置, 请根据PA3中的讲义内容检查你的代码实现.
为了测试实现的正确性, 我们先单独运行dummy(别忘记修改调度代码),
并先在exit的实现中调用halt()结束系统的运行,
这是因为让其它程序成功运行还需要进行一些额外的改动.
如果你的实现正确, 你会看到dummy程序最后输出GOOD TRAP的信息, 说明它确实在分页机制上成功运行了.
让DiffTest支持分页机制(2)
如果你选择的是riscv32, 为了让DiffTest机制正确地支持用户进程的运行, 你还需要:
- 实现
M和U两种特权级模式, 具体地- 在NEMU中实现
mstatus.MPP位的功能 - 执行
ecall指令时, 根据当前特权级抛出不同号码的异常, 但在CTE中对它们进行统一的处理 - 创建内核线程上下文时, 额外将
mstatus.MPP设置为M模式 - 创建用户进程上下文时, 额外将
mstatus.MPP设置为U模式
- 在NEMU中实现
- 填写页表时, 需要额外设置
R,W,X,U,A,D位 - 创建用户进程上下文时, 为
mstatus额外设置MXR和SUM位
内核映射的作用
对于x86和riscv32, 在protect()中创建地址空间的时候, 有一处代码用于拷贝内核映射:
// map kernel space
memcpy(updir, kas.ptr, PGSIZE);
尝试注释这处代码, 重新编译并运行, 你会看到发生了错误. 请解释为什么会发生这个错误.
为了在分页机制上运行仙剑奇侠传, 我们还需要考虑堆区的问题.
之前我们让mm_brk()函数直接返回0, 表示用户进程的堆区大小修改总是成功,
这是因为在实现分页机制之前, 0x3000000/0x83000000之上的内存都可以让用户进程自由使用.
现在用户进程运行在分页机制之上, 我们还需要在mm_brk()中把新申请的堆区映射到虚拟地址空间中,
这样才能保证运行在分页机制上的用户进程可以正确地访问新申请的堆区.
为了识别堆区中的哪些空间是新申请的, 我们还需要记录堆区的位置.
由于每个进程的堆区使用情况是独立的, 我们需要为它们分别维护堆区的位置,
因此我们在PCB中添加成员max_brk, 来记录program break曾经达到的最大位置.
引入max_brk是为了简化实现: 我们可以不实现堆区的回收功能,
而是只为当前新program break超过max_brk部分的虚拟地址空间分配物理页.
在分页机制上运行仙剑奇侠传
根据上述内容, 实现nanos-lite/src/mm.c中的mm_brk()函数.
你需要注意map()参数是否需要按页对齐的问题(这取决于你的map()实现).
实现正确后, 仙剑奇侠传就可以正确在分页机制上运行了.
一致性问题 - mips32的噩梦来了
分页的道理也说得差不多了, 但如果你选择的是mips32, 在运行仙剑奇侠传的过程中, 你应该会遇到各种奇怪的问题, 而且不少问题可能都是一致性问题导致的. 在这里, TLB中的内容可以说是内存页表项的副本...
噢, 既然你有决心选择mips32, 我们就不透露那么多了, 尝试自己把这个问题理清楚, 并思考相应的解决方案吧. 解决了一致性问题, 才能说得上对mips32的分页机制有彻底的理解.
native的VME实现
尝试阅读native的VME实现, 你发现native是如何实现VME的? 为什么可以这样做?
可以在用户栈里面创建用户进程上下文吗?
ucontext()的行为是在内核栈kstack中创建用户进程上下文.
我们是否可以对ucontext()的行为进行修改, 让它在用户栈上创建用户进程上下文? 为什么?
支持虚存管理的多道程序
绕了一大圈引入了虚存管理, 现在我们终于回来了: 我们可以支持多个用户进程的并发执行了. 不过我们还是先让运行在分页机制上的用户进程和内核线程并发执行, 来对分页机制进行进一步的测试.
为此, 我们需要思考内核线程的调度会对分页机制造成什么样的影响.
内核线程和用户进程最大的不同, 就是它没有用户态的地址空间:
内核线程的代码, 数据和栈都是位于内核的地址空间.
那在启动分页机制之后, 如果__am_irq_handle()要返回一个内核线程的现场,
我们是否需要考虑通过__am_switch()切换到内核线程的虚拟地址空间呢?
答案是, 不需要. 这是因为AM创建的所有虚拟地址空间都会包含内核映射,
无论在切换之前是位于哪一个虚拟地址空间, 内核线程都可以在这个虚拟地址空间上正确运行.
因此我们只要在kcontext()中将上下文的地址空间描述符指针设置为NULL,
来进行特殊的标记, 等到将来在__am_irq_handle()中调用__am_switch()时,
如果发现地址空间描述符指针为NULL, 就不进行虚拟地址空间的切换.
支持虚存管理的多道程序
让Nanos-lite加载运行仙剑奇侠传和内核线程hello. 此时的运行效果和上一阶段一样, 但这次整个系统都是运行在分页机制之上的.
不过我们会发现, 和之前相比, 在分页机制上运行的仙剑奇侠传的性能有了明显的下降. 尽管NEMU在串行模拟MMU的功能, 并不能完全代表硬件MMU的真实运行情况, 但这也说明了虚存机制确实会带来额外的运行时开销. 由于这个原因, 60年代的工程师普遍对虚存机制有所顾虑, 不敢轻易在系统中实现虚存机制. 但"不必修改程序即可让多个程序并发运行"的好处越来越明显, 以至于虚存机制成为了现代计算机系统的标配.
并发执行多个用户进程
让Nanos-lite加载仙剑奇侠传和hello这两个用户进程; 或者是加载NTerm和hello内核线程, 然后从NTerm启动仙剑奇侠传, 你应该会在运行的时候观察到错误. 尝试分析这一错误的原因, 并总结为了支持这一功能, 我们需要满足什么样的条件.
这可以说是一周目最难的一道思考题了, 虽然我们会在PA4的最后给出分析, 喜欢挑战的同学仍然可以在这里尝试独立思考: 如果你能独立解决这个问题, 说明你对计算机系统的理解可以说是相当了得了.
Hint: 程序是个状态机.
这一阶段的内容算是整个PA中最难的了, 连选做题的难度和之前比也不是一个量级的. 这也展示了构建系统的挑战: 随着一个系统趋于完善, 模块之间的交互会越来越复杂, 代码看似避繁就简却可谓字字珠玑, 牵一发而动全身. 不过这是项目复杂度上升的必然规律, 等到代码量到了一定程度, 即使是开发一个应用程序, 也会面临类似的困难. 那我们要如何理解和管理规模日趋复杂的项目代码呢?
答案是抽象. 所以你在PA中看到各种各样的API, 我们并不是随随便便定义它们的, 它们确实蕴含了模块行为的本质, 从而帮助我们更容易地从宏观的角度理解整个系统的行为, 就算是调试, 这些API对我们梳理代码的行为也有巨大的帮助. 当你在理解, 实现, 调试这些API的过程中, 你对整个系统的认识也会越来越深刻. 如果你确实独立完成到这里, 就算你以后面对更复杂的项目, 相信你也不会畏惧了.
温馨提示
PA4阶段2到此结束.